

在本文中,你将了解:
- Bright Data 在 Databricks 上提供了哪些产品。
- 如何设置 Databricks 帐号,并获取以编程方式检索与探索数据所需的全部凭据。
- 如何使用 Databricks 的以下方式查询 Bright Data 数据集:
- REST API
- CLI
- SQL 连接器
开始吧!
Bright Data 在 Databricks 上的数据产品
Databricks 是一个开放的分析平台,用于大规模构建、部署、共享和维护企业级数据、分析与 AI 解决方案。在其网站上,你可以找到来自多个提供商的数据产品,因此它被认为是最好的数据市场之一。
Bright Data 近日加入 Databricks 成为数据产品提供商,目前已提供 40 多种产品:
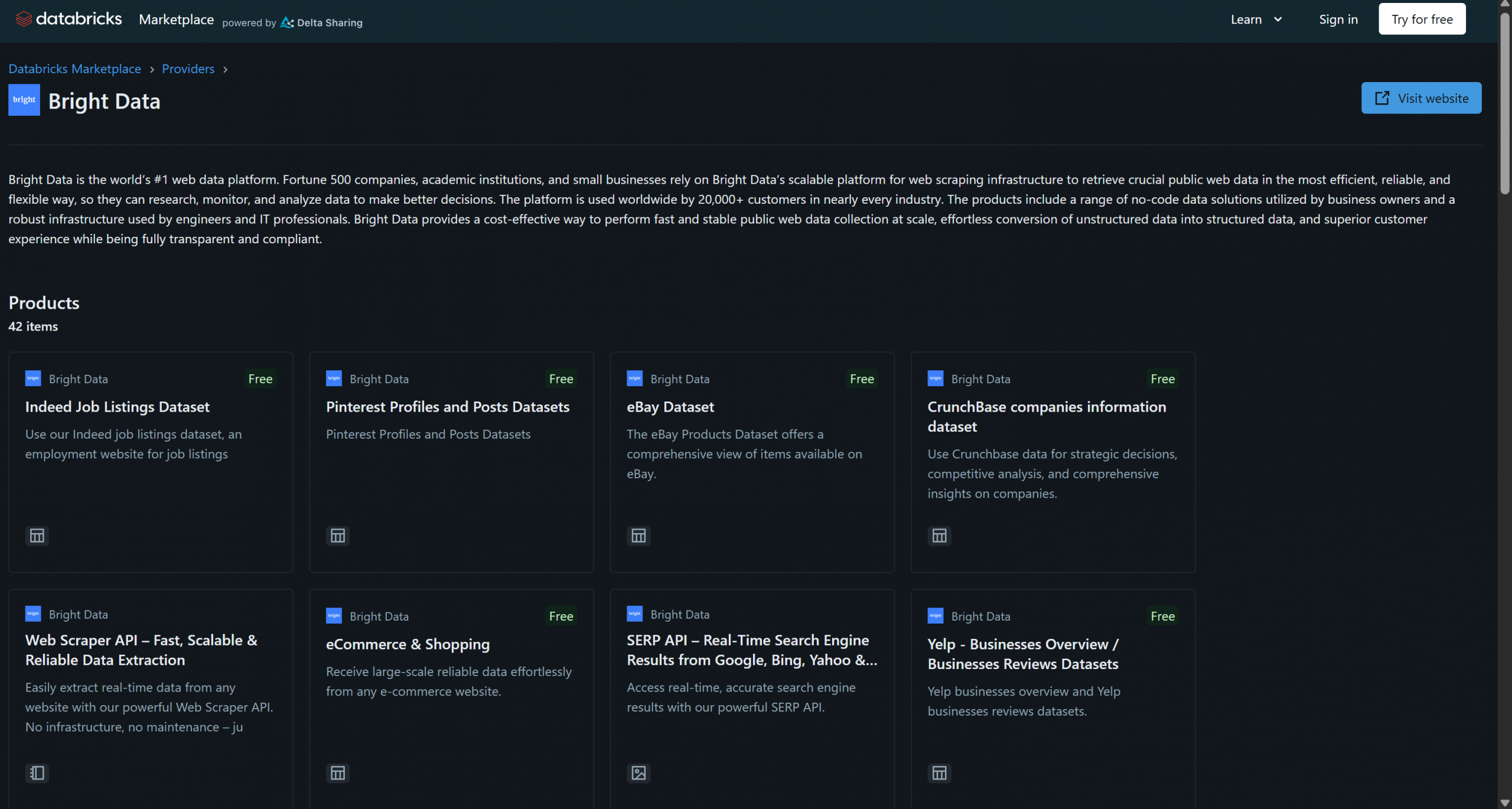
这些解决方案包括B2B 数据集、公司数据集、金融数据集、房地产数据集等。此外,你还可以通过 Bright Data 的基础设施访问更通用的网页数据获取与爬取方案,如 Scraping Browser 和 Web Scraper API。
在本教程中,你将学习如何使用 Databricks 的 API、CLI 和专用的 SQL 连接器库,以编程方式从这些 Bright Data 数据集之一中查询数据。让我们开始吧!
Databricks 入门
要通过 API 或 CLI 从 Databricks 查询 Bright Data 数据集,首先需要进行一些设置。按照下面的步骤配置你的 Databricks 帐号,并获取访问与集成 Bright Data 数据集所需的全部凭据。
在本节结束时,你将获得:
- 已配置的 Databricks 帐号
- Databricks 访问令牌
- Databricks 仓库 ID
- Databricks 主机地址字符串
- 在 Databricks 帐号中对一个或多个 Bright Data 数据集的访问权限
先决条件
首先,确保你拥有 Databricks 帐号(免费帐号即可)。如果还没有,请创建一个帐号;否则,直接登录。
配置你的 Databricks 访问令牌
要授权访问 Databricks 资源,你需要一个访问令牌。按以下说明进行设置。
在 Databricks 控制台中,点击个人头像,选择“Settings(设置)”选项:
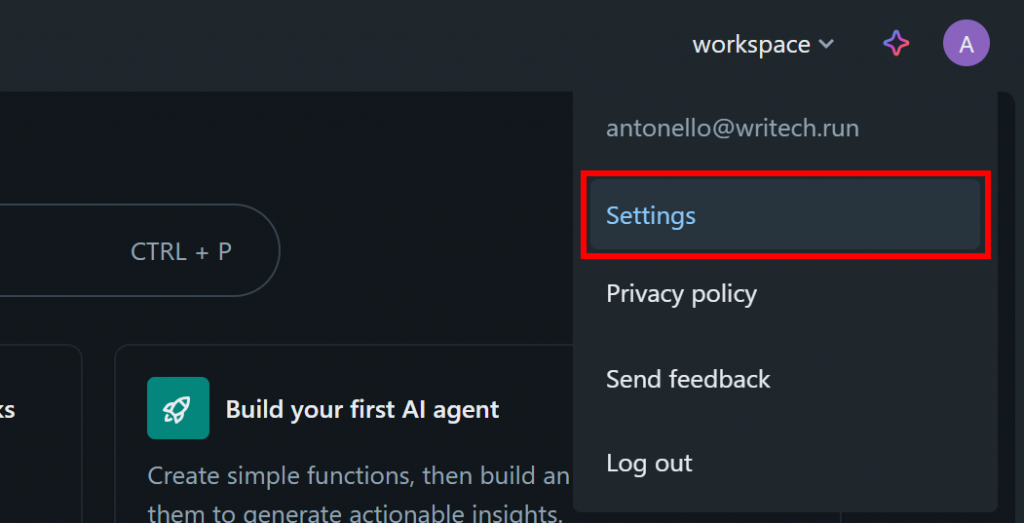
在“Settings(设置)”页面,选择“Developer(开发者)”,然后在“Access tokens(访问令牌)”部分点击“Manage(管理)”按钮:
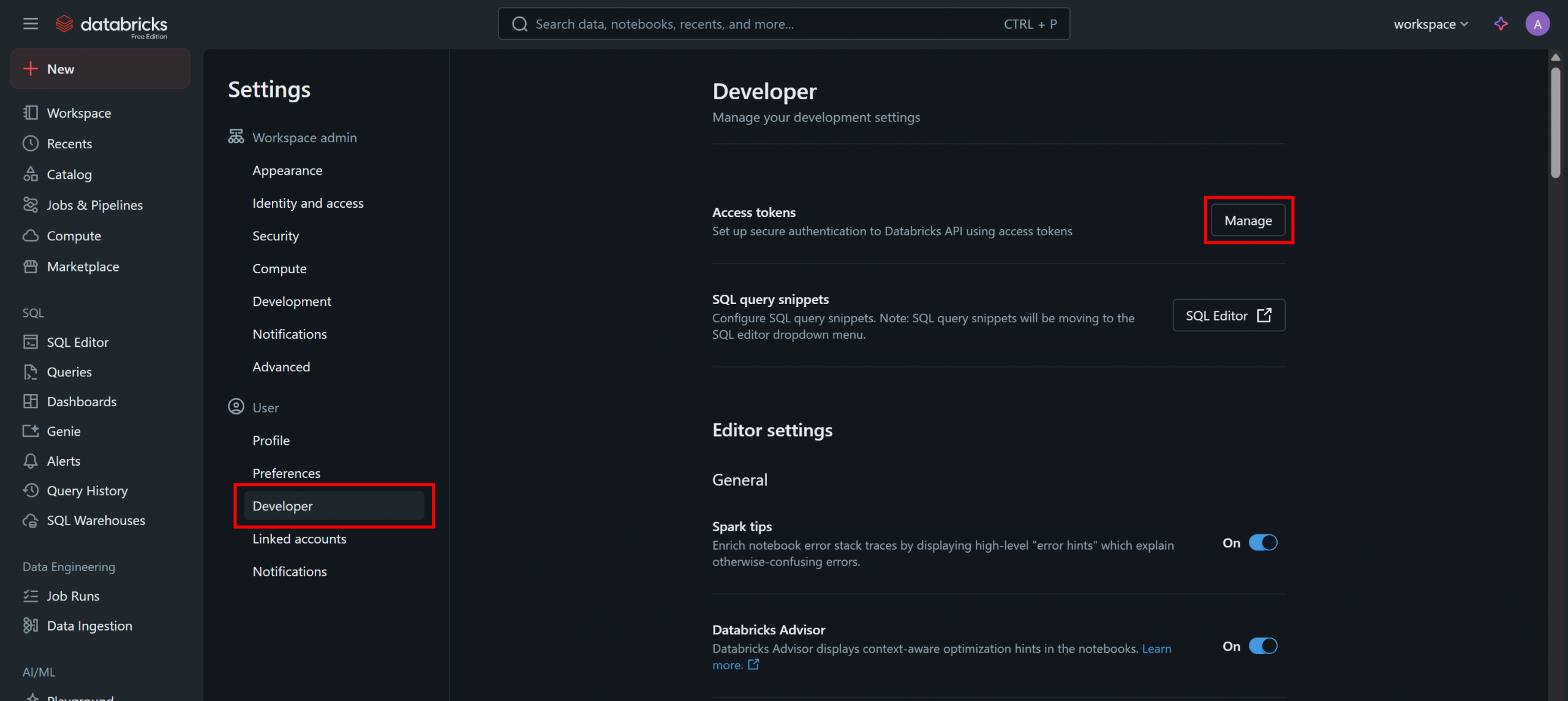
在“Access tokens(访问令牌)”页面,点击“Generate New Token(生成新令牌)”,并按照弹窗中的说明操作:
你将获得一个 Databricks API 访问令牌。妥善保存,稍后会用到。
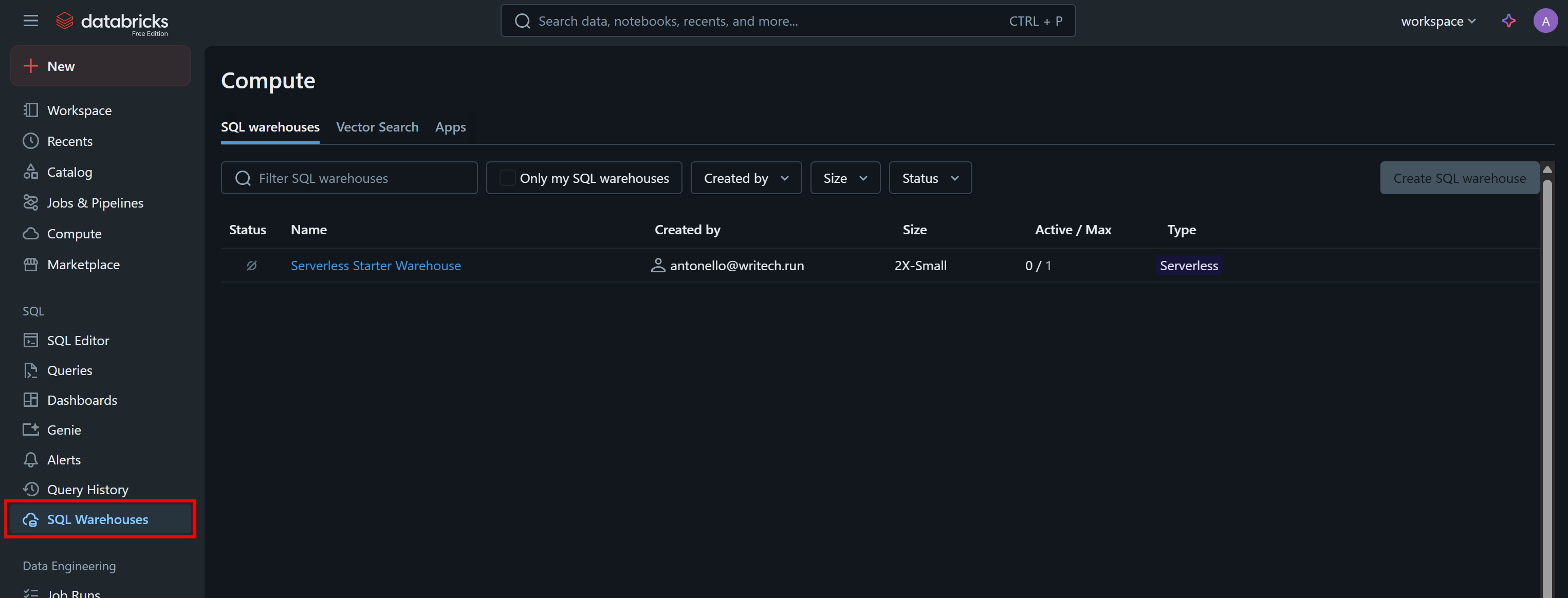
获取你的 Databricks 仓库 ID
通过 API 或 CLI 查询数据集时,你还需要 Databricks 仓库 ID。要获取它,在菜单中选择“SQL Warehouses(SQL 仓库)”选项:
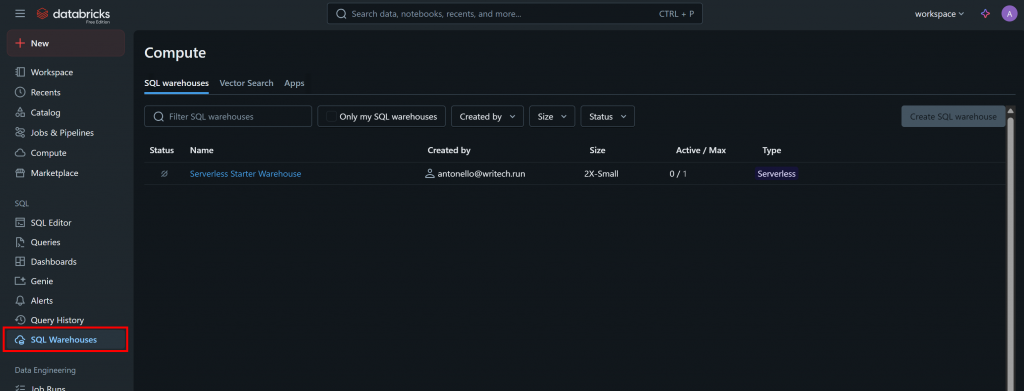
点击可用的仓库(本示例为“Serverless Starter Warehouse”),进入“Overview(概览)”选项卡:
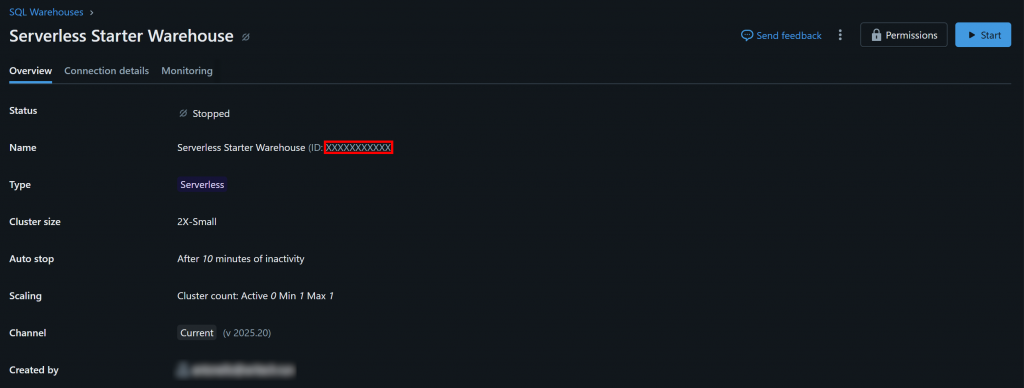
在“Name(名称)”部分,你会看到 Databricks 仓库 ID(括号中,位于 ID: 之后)。复制并妥善保存,稍后会用到。
查找你的 Databricks 主机
要连接到任意 Databricks 计算资源,你需要指定 Databricks 主机名。它对应与你的 Databricks 帐号关联的基础 URL,格式类似于:
https://<random-string>.cloud.databricks.com你可以直接从 Databricks 控制台的地址栏复制该信息:

获取 Bright Data 数据集的访问权限
现在,你需要将一个或多个 Bright Data 数据集添加到你的 Databricks 帐号,以便通过 API、CLI 或 SQL 连接器进行查询。
进入“Marketplace(市场)”页面,点击左侧的设置按钮,将提供商筛选为仅“Bright Data”:
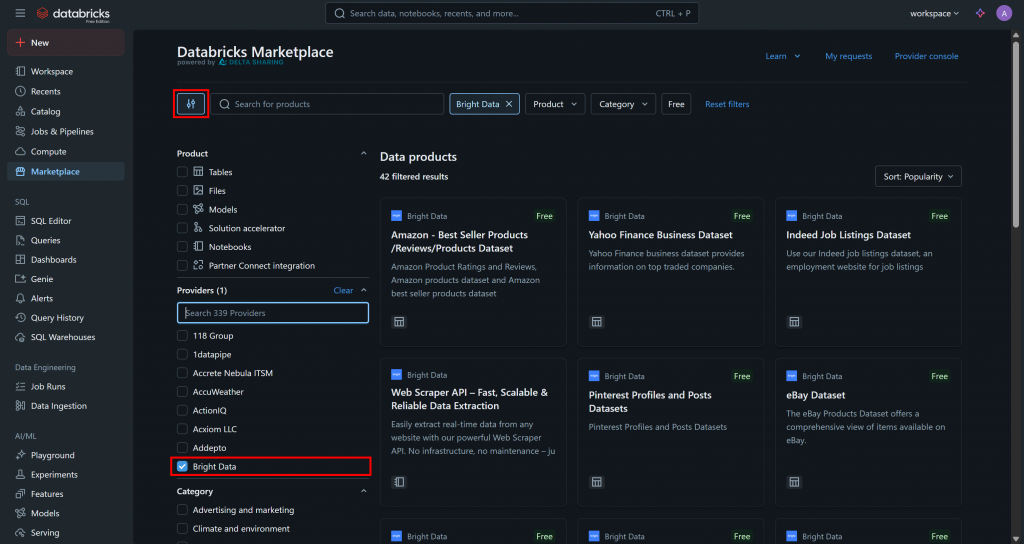
这将把可用数据产品过滤为仅由 Bright Data 提供且可在 Databricks 上访问的那些。
例如,假设你对“Zillow Properties Information Dataset(Zillow 房产信息数据集)”感兴趣:
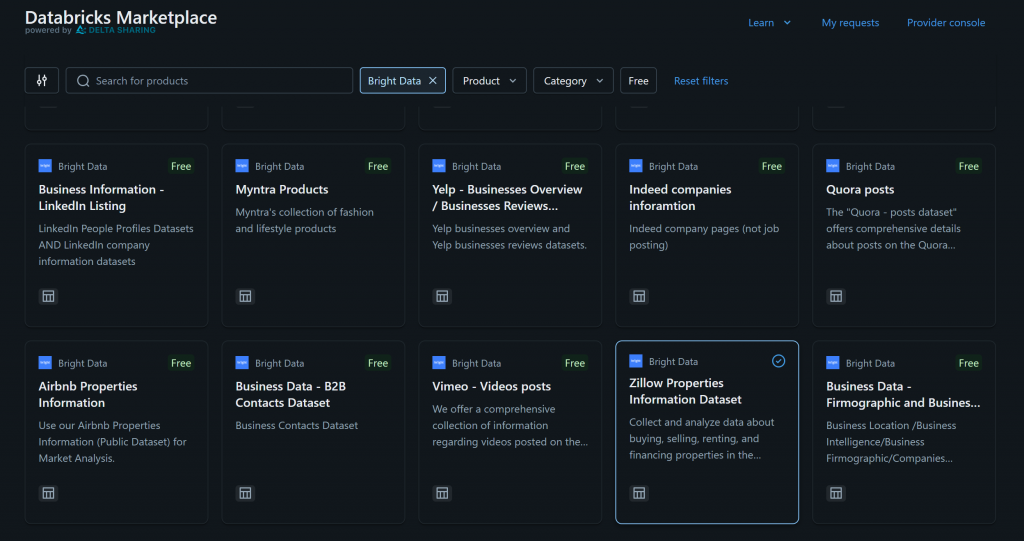
点击该数据集卡片,在“Zillow Properties Information Dataset”页面,点击“Get instant access(立即获取访问权限)”将其添加到你的 Databricks 帐号:
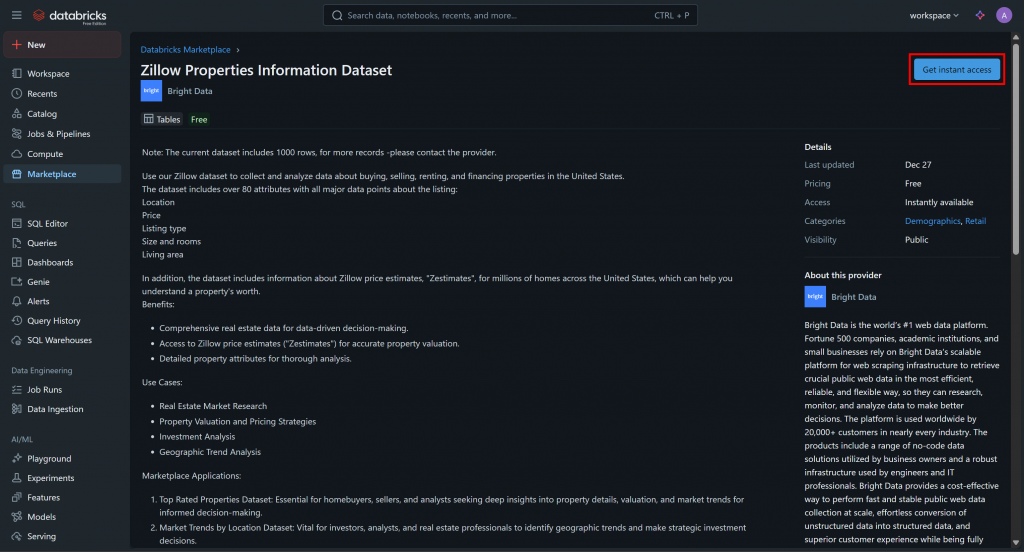
数据集将被添加到你的帐号中,你现在可以通过Databricks SQL对其进行查询。如果你想知道这些数据来自哪里,答案是Bright Data 的 Zillow 数据集。
你可以进入“SQL Editor(SQL 编辑器)”页面,使用如下 SQL 语句查询该数据集进行验证:
SELECT * FROM bright_data_zillow_properties_information_dataset.datasets.zillow_properties
WHERE state LIKE 'NY' AND homestatus LIKE 'FOR_SALE'
LIMIT 10;结果应类似于:
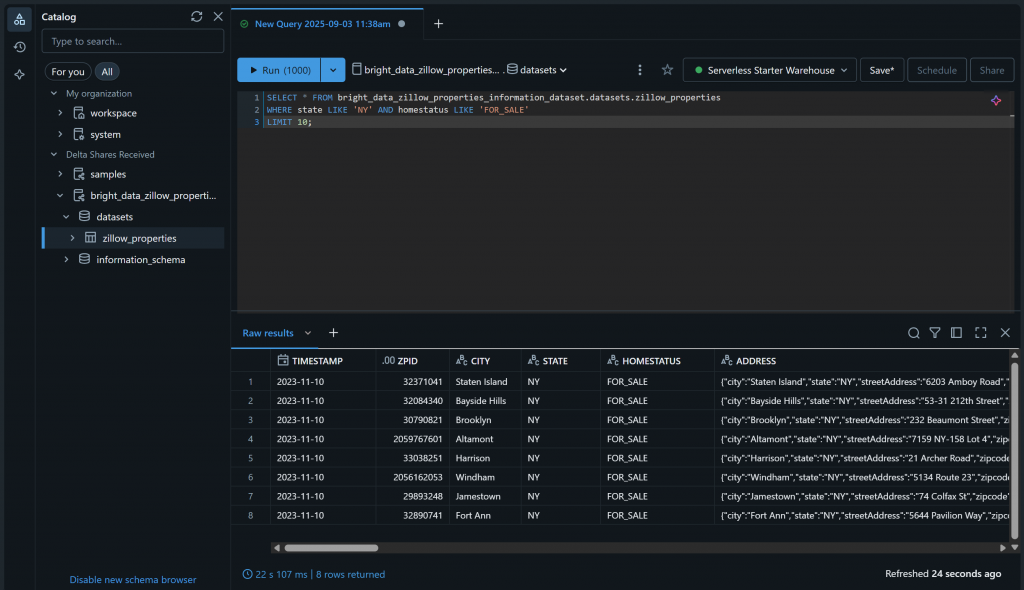
很好!你已成功添加所选 Bright Data 数据集,并使其可在 Databricks 中进行查询。你也可以按照相同步骤添加其他 Bright Data 数据集。
接下来,你将学习如何通过以下方式查询该数据集:
- 通过 Databricks REST API
- 使用 Databricks SQL Connector for Python
- 通过 Databricks CLI
通过 Databricks REST API 查询 Bright Data 数据集
Databricks 通过REST API暴露了部分功能,其中包括查询你帐号中可用的数据集。按照以下步骤,查看如何以编程方式查询由 Bright Data 提供的“Zillow Properties Information Dataset”。
注意:下面的代码使用 Python 编写,但也可以轻松适配为其他编程语言,或直接在 Bash 中通过 cURL 调用。
步骤一:安装所需库
要在远程 Databricks 仓库上运行 SQL 查询,需要使用/api/2.0/sql/statements 端点。你可以用任意 HTTP 客户端通过 POST 请求调用它。本文示例将使用 Python 的 Requests 库。
使用以下命令安装:
pip install requests然后在脚本中导入:
import requests了解更多内容,请参阅我们关于 Python Requests 的指南。
步骤二:准备 Databricks 凭据与密钥
通过 HTTP 客户端调用 /api/2.0/sql/statements 端点时,需要提供:
- Databricks 访问令牌:用于身份验证。
- Databricks 主机:用于构建完整的 API URL。
- Databricks 仓库 ID:用于在正确的仓库中查询正确的表。
将之前获取的密钥按如下方式添加到你的脚本中:
databricks_access_token = "<YOUR_DATABRICKS_ACCESS_TOKEN>"
databricks_warehouse_id = "<YOUR_DATABRICKS_WAREHOUSE_ID>"
databricks_host = "<YOUR_DATABRICKS_HOST>"提示:在生产环境中,避免将这些密钥硬编码在脚本中。建议将凭据存储在环境变量中,并通过python-dotenv 加载,以提升安全性。
步骤三:调用 SQL 语句执行 API
使用 Requests 向 /api/2.0/sql/statements 端点发起POST 请求,携带合适的请求头与请求体:
# The parametrized SQL query to run on the given dataset
sql_query = """
SELECT *
FROM bright_data_zillow_properties_information_dataset.datasets.zillow_properties
WHERE state LIKE :state AND homestatus LIKE :homestatus
LIMIT :row_limit;
"""
# The parameter to populate the SQL query
parameters = [
{"name": "state", "value": "NY", "type": "STRING"},
{"name": "homestatus", "value": "FOR_SALE", "type": "STRING"},
{"name": "row_limit", "value": "10", "type": "INT"}
]
# Make the POST request and query the dataset
headers = {
"Authorization": f"Bearer {databricks_access_token}", # For authenticating in Databricks
"Content-Type": "application/json"
}
payload = {
"statement": sql_query,
"warehouse_id": databricks_warehouse_id,
"parameters": parameters
}
response = requests.post(
f"{databricks_host}/api/2.0/sql/statements",
headers=headers,
data=json.dumps(payload)
)如你所见,上述代码段基于预备(参数化)SQL 语句。正如文档中强调的,Databricks 强烈建议在 SQL 语句中使用参数化查询,这是一项最佳实践。
换句话说,运行上述脚本等同于在 bright_data_zillow_properties_information_dataset.datasets.zillow_properties 表上执行以下查询,就像我们之前所做的那样:
SELECT * FROM bright_data_zillow_properties_information_dataset.datasets.zillow_properties
WHERE state LIKE 'NY' AND homestatus LIKE 'FOR_SALE'
LIMIT 10;太棒了!接下来只需处理输出数据。
步骤四:导出查询结果
使用以下 Python 逻辑处理响应并导出检索到的数据:
if response.status_code == 200:
# Access the output JSON data
result = response.json()
# Export the retrieved data to a JSON file
output_file = "zillow_properties.json"
with open(output_file, "w", encoding="utf-8") as f:
json.dump(result, f, indent=4)
print(f"Query successful! Results saved to '{output_file}'")
else:
print(f"Error {response.status_code}: {response.text}")如果请求成功,该代码将创建一个包含查询结果的 zillow_properties.json 文件。
步骤五:整合所有内容
最终脚本应如下所示:
import requests
import json
# Your Databricks credentials (replace them with the right values)
databricks_access_token = "<YOUR_DATABRICKS_ACCESS_TOKEN>"
databricks_warehouse_id = "<YOUR_DATABRICKS_WAREHOUSE_ID>"
databricks_host = "<YOUR_DATABRICKS_HOST>"
# The parametrized SQL query to run on the given dataset
sql_query = """
SELECT *
FROM bright_data_zillow_properties_information_dataset.datasets.zillow_properties
WHERE state LIKE :state AND homestatus LIKE :homestatus
LIMIT :row_limit;
"""
# The parameter to populate the SQL query
parameters = [
{"name": "state", "value": "NY", "type": "STRING"},
{"name": "homestatus", "value": "FOR_SALE", "type": "STRING"},
{"name": "row_limit", "value": "10", "type": "INT"}
]
# Make the POST request and query the dataset
headers = {
"Authorization": f"Bearer {databricks_access_token}", # For authenticating in Databricks
"Content-Type": "application/json"
}
payload = {
"statement": sql_query,
"warehouse_id": databricks_warehouse_id,
"parameters": parameters
}
response = requests.post(
f"{databricks_host}/api/2.0/sql/statements",
headers=headers,
data=json.dumps(payload)
)
# Handle the response
if response.status_code == 200:
# Access the output JSON data
result = response.json()
# Export the retrieved data to a JSON file
output_file = "zillow_properties.json"
with open(output_file, "w", encoding="utf-8") as f:
json.dump(result, f, indent=4)
print(f"Query successful! Results saved to '{output_file}'")
else:
print(f"Error {response.status_code}: {response.text}")运行后,应在项目目录中生成 zillow_properties.json 文件。
输出首先包含列结构,帮助你理解可用列。随后在 data_array 字段中,你可以看到以 JSON 字符串形式呈现的查询结果数据:
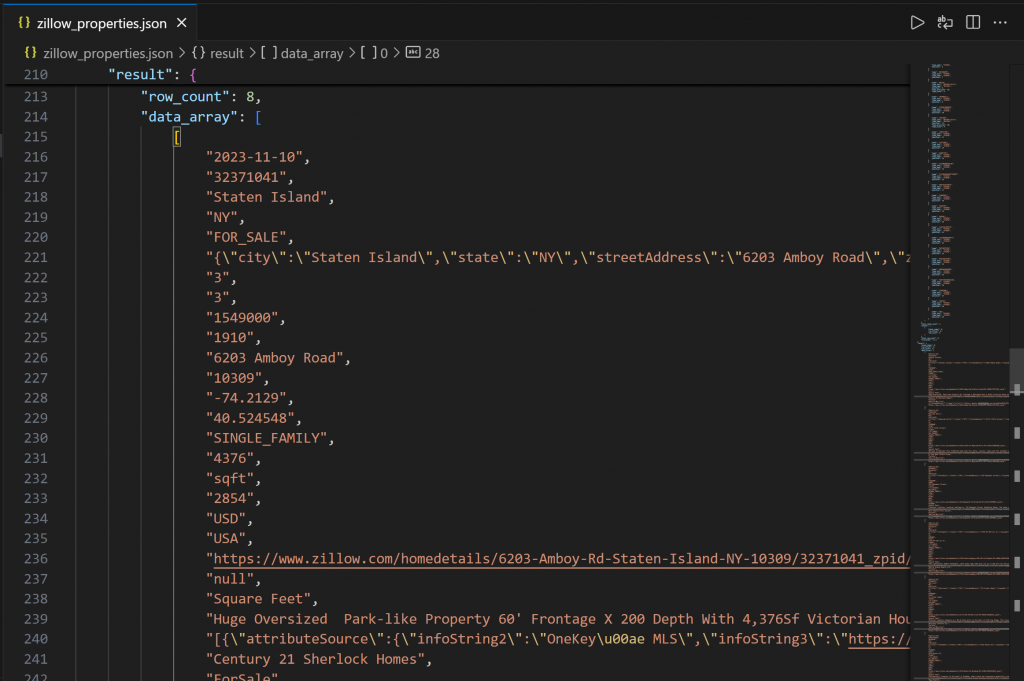
任务完成!你刚刚通过 Databricks REST API 采集了由 Bright Data 提供的 Zillow 房产数据。
使用 Databricks CLI 访问 Bright Data 数据集
Databricks 还允许你通过Databricks CLI 查询仓库中的数据,该工具底层依赖 REST API。下面来学习如何使用它!
步骤一:安装 Databricks CLI
Databricks CLI 是一个开源命令行工具,使你可以在终端中直接与 Databricks 平台交互。
安装方法请按照适用于你的操作系统的安装指南进行。如果一切配置正确,运行 databricks -v 命令应看到类似如下的输出:

完美!
步骤二:定义用于认证的配置档案
使用 Databricks CLI 创建一个名为 DEFAULT 的配置档案,通过你的 Databricks 个人访问令牌进行认证。运行如下命令:
databricks configure --profile DEFAULT随后系统会提示你输入:
- Databricks 主机
- Databricks 访问令牌
粘贴两项值并按 Enter 完成配置:

此后,你可以通过指定 --profile DEFAULT 来为CLI 的 api 命令完成身份验证。
步骤三:查询你的数据集
使用以下 CLI 命令,通过api post 命令运行参数化查询:
databricks api post "/api/2.0/sql/statements"
--profile DEFAULT
--json '{
"warehouse_id": "<YOUR_DATABRICKS_WAREHOUSE_ID>",
"statement": "SELECT * FROM bright_data_zillow_properties_information_dataset.datasets.zillow_properties WHERE state LIKE :state AND homestatus LIKE :homestatus LIMIT :row_limit",
"parameters": [
{ "name": "state", "value": "NY", "type": "STRING" },
{ "name": "homestatus", "value": "FOR_SALE", "type": "STRING" },
{ "name": "row_limit", "value": "10", "type": "INT" }
]
}'
> zillow_properties.json将 <YOUR_DATABRICKS_WAREHOUSE_ID> 替换为你的 Databricks SQL 仓库的实际 ID。
在幕后,这与我们之前在 Python 中所做的操作相同:向 Databricks REST SQL API 发送一条 POST 请求。输出将是一个 zillow_properties.json 文件,包含先前相同的数据:
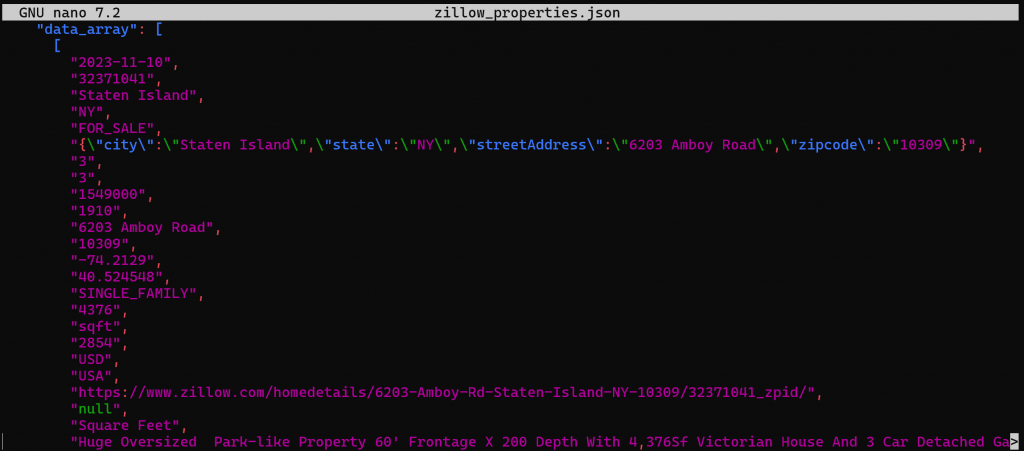
通过 Databricks SQL 连接器查询 Bright Data 的数据集
Databricks SQL Connector 是一个 Python 库,可让你连接到 Databricks 集群与 SQL 仓库。它提供了简化的 API,用于连接 Databricks 基础设施并探索你的数据。
在本节中,你将学习如何使用它来查询 Bright Data 的“Zillow Properties Information Dataset”。
步骤一:安装 Databricks SQL Connector for Python
Databricks SQL 连接器通过 databricks-sql-connector 发布。使用以下命令安装:
pip install databricks-sql-connector然后在脚本中导入:
from databricks import sql步骤二:开始使用 Databricks SQL 连接器
与 REST API 和 CLI 相比,Databricks SQL 连接器需要不同的凭据,具体为:
server_hostname:你的 Databricks 主机名(不包含https://)。http_path:连接到你的仓库的专用 URL。access_token:你的 Databricks 访问令牌。
你可以在 SQL 仓库的“Connection Details(连接详情)”选项卡中找到所需的认证信息及示例入门代码片段:
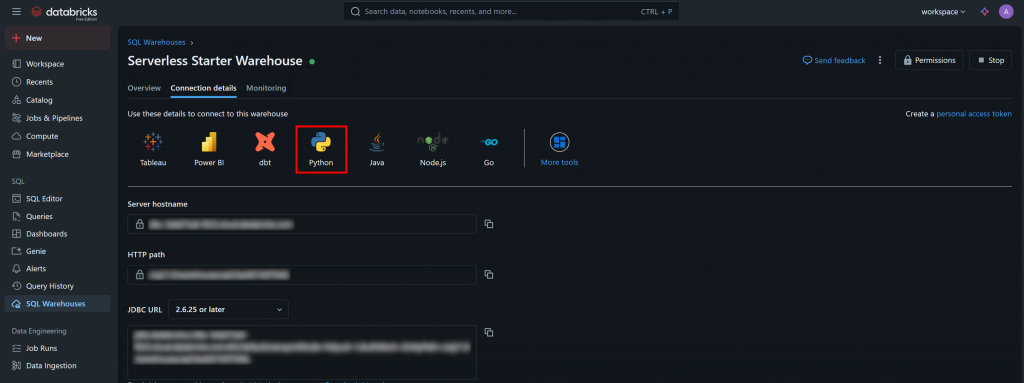
点击“Python”按钮,你将看到:
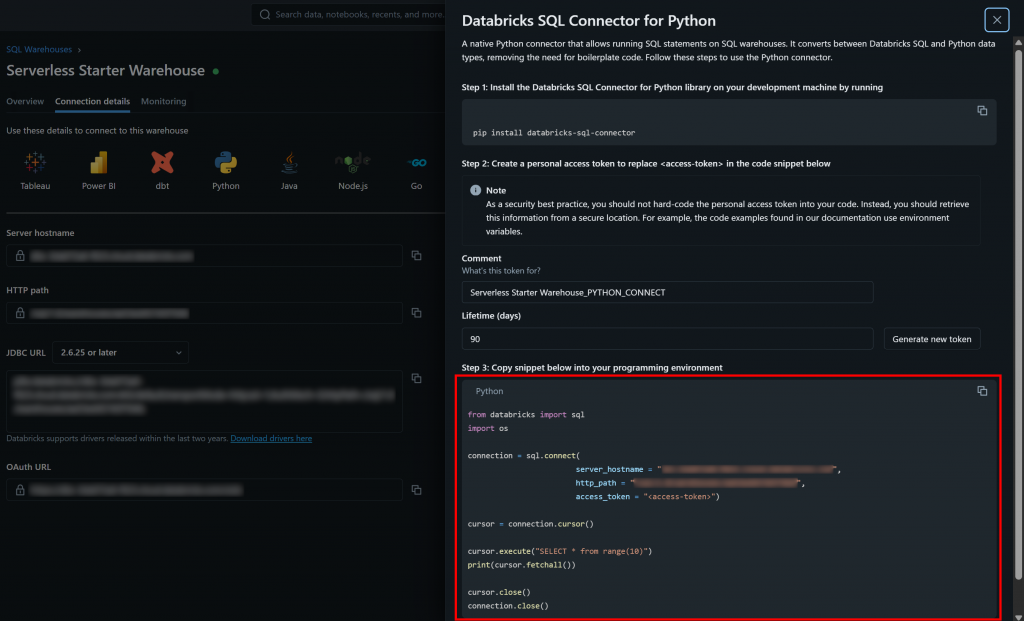
这就是开始使用 databricks-sql-connector 所需的全部说明。
步骤三:整合所有内容
基于“Databricks SQL Connector for Python”部分提供的示例片段,替换为你的仓库凭据以运行参数化查询。最终脚本示例如下:
from databricks import sql
# Connect to your SQL warehouse in Databricks (replace the credentials with your values)
connection = sql.connect(
server_hostname = "<YOUR_DATABRICKS_HOST>",
http_path = "<YOUR_DATABRICKS_WAREHOUST_HTTP_PATH>",
access_token = "<YOUR_DATABRICKS_ACCESS_TOKEN>"
)
# Execute the SQL parametrized query and get the results in a cursor
cursor = connection.cursor()
sql_query = """
SELECT *
FROM bright_data_zillow_properties_information_dataset.datasets.zillow_properties
WHERE state LIKE :state AND homestatus LIKE :homestatus
LIMIT :row_limit
"""
params = {
"state": "NY",
"homestatus": "FOR_SALE",
"row_limit": 10
}
# Run the query
cursor.execute(sql_query, params)
result = cursor.fetchall()
# Printing all results a row at a time
for row in result[:2]:
print(row)
# Close the cursor and the SQL warehouse connection
cursor.close()
connection.close()运行脚本,将输出类似如下的结果:
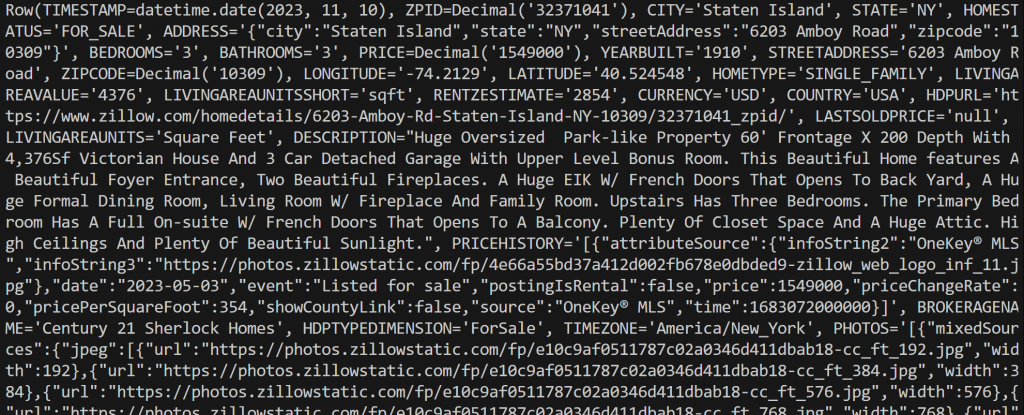
注意,每个 row 对象都是一个Row 实例,代表查询结果中的一条记录。你可以在 Python 脚本中直接处理这些数据。
你可以使用 asDict() 方法将 Row 实例转换为 Python 字典:
row_data = row.asDict()搞定!现在你已经掌握了在 Databricks 中以多种方式与 Bright Data 数据集交互和查询的方法。
结论
在本文中,你学习了如何通过 Databricks 的 REST API、CLI 或专用 SQL 连接器库查询 Bright Data 的数据集。事实证明,Databricks 为其数据提供商所提供的产品提供了多种交互方式,Bright Data 现已成为其中一员。
目前已有 40 多个产品可用,你可以在 Databricks 内直接探索丰富多样的Bright Data 数据集,并以多种方式访问这些数据。
立即免费创建 Bright Data 帐号,开始体验我们的数据解决方案吧!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




