

在本指南中,您将学习到以下内容:
- Dify 是什么?
- 这就是为什么你应该将它与一体化搜索插件整合在一起的原因。
- 将 Dify 与 Bright Data scraping 插件集成的好处。
- 创建 Dify 搜索工作流程的分步教程。
让我们深入了解一下!
Dify:低代码人工智能开发的力量
Dify是一个开源 LLM 应用程序开发平台。它是一个 LLM-ops 解决方案,可简化人工智能应用程序的创建。
更具体地说,它通过提供以下功能,帮助开发人员构建和启动随时可用的代理人工智能应用程序:
- 可视化工作流程生成器:使用拖放界面设计多步骤人工智能流程。您可以将不同的模型、工具和逻辑串联在一起,而不会被模板代码所困扰。
- 与模型无关:与各种 LLM 集成,从 OpenAI 的 GPT 系列等专有模型到各种开源替代方案。这样,您就可以灵活地选择最适合您使用情况的模型。
- 后台即服务(BaaS):处理托管、扩展和管理后端基础设施的复杂问题。这样,您就可以专注于利用人工智能的功能,而不是管理底层基础设施。
- 可扩展性:通过第三方供应商提供的插件和定制工具,轻松扩展功能。这使得 Dify 能够适应各种使用情况。
在 Dify 中使用专用扫描插件的必要性
大规模网络抓取带来了许多挑战。网站使用的反僵尸措施很容易阻止简单的数据检索尝试。因此,建立和维护一个克服这些障碍的系统既复杂又耗费资源。
这正是Bright Data Dify 插件发挥作用的地方。该插件可处理从代理轮换和 IP 管理到验证码和数据解析等所有底层复杂问题。换句话说,它能确保您的 Dify 代理接收到一致、高质量的网络数据。
具体来说,Bright Data 插件提供了这些工具:
- 结构化数据源:从 50 多个平台获取结构化、有组织的数据,如电子商务产品页面或房地产列表。
- Scrape as markdown:它能去除广告、导航栏和其他非必要元素,提供简洁的标记符格式文本。
- 搜索引擎工具:直接在 Google、Bing、Yandex 等搜索引擎上进行查询。您可以用它来监控特定关键词的搜索排名,发现竞争对手的内容,或在SERP RAG 工作流中使用。
将 Dify 与 Bright Data 插件整合的优势
当您将 Dify 的人工智能协调功能与 Bright Data 的抓取功能连接起来时,您就可以释放这一功能:
- 访问实时数据:您的人工智能代理可以通过实时网络查询最新信息,而不是依赖过时的数据。这可确保您的人工智能应用程序使用最新数据运行。
- 将复杂的研究和分析自动化:通过将数据直接输入 Dify 工作流程中的 LLM,您可以自动执行原本需要数小时手动工作的任务。例如,您可以建立一个 RAG 工作流程,以监控电子商务网站上的竞争对手产品列表。
- 简化技术复杂性:网络抓取并不容易,因为网站会采用复杂的反抓取拦截技术。Bright Data 插件可为您避免这些拦截。所有这一切,Dify 都能提供简单的界面来利用这一功能。
- 多功能,适用于各种使用情况:该插件可为您提供多种工具,包括获取结构化数据、刮除任何页面以清除标记和执行搜索引擎查询。这使得 Dify + Bright Data 集成可适用于多种使用情况。
将 Dify 与 Bright Data 集成,实现产品汇总:逐步教程
是时候一步步学习如何使用 Dify 和 Bright Data 之间的集成了。
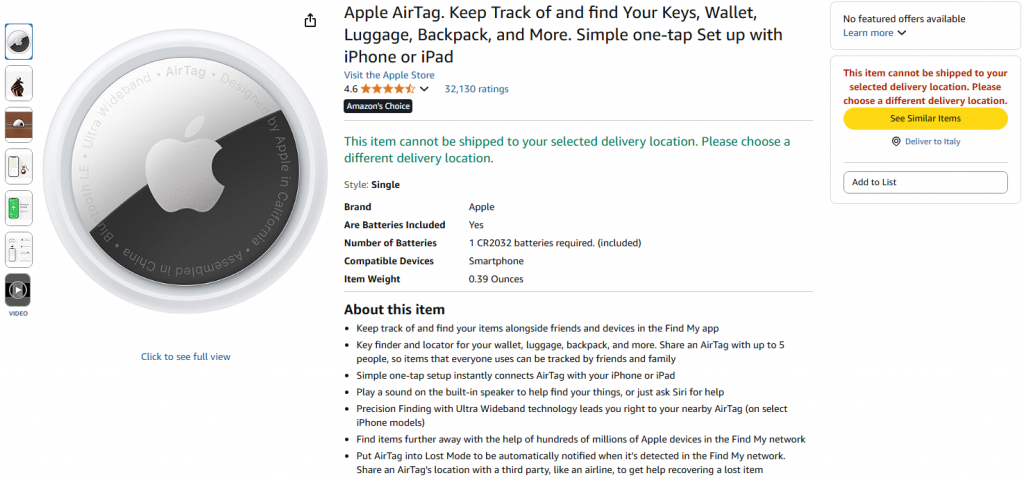
您要创建的工作流程的目标是将亚马逊产品作为输入,并接收其摘要。您要使用的产品来自亚马逊,是一个Apple AirTag:
为实现人工智能扫描目标,您将通过连接不同节点来构建一个四阶段工作流程。每个节点都有特定的工作:
- 一个 “开始 “节点,用于定义输入变量,即亚马逊产品页面的 URL。
- 结构化数据馈送 “节点将使用该 URL 并抓取其内容,从亚马逊页面中提取所有结构化数据。
- LLM” 节点用于处理搜索到的数据。您将向它发出生成产品摘要的特定提示。
- 一个 “结束 “节点,用于显示 LLM 生成的摘要文本。
整个四步 AI 搜索过程完全可视化。您将在一个简单的流程中连接这些节点,而且无需编写任何代码。
请按照说明在 Dify 中构建由 Bright Data 驱动的无代码网页抓取人工智能工作流!
要求
要重现本教程,了解如何将 Dify 与 Bright Data 集成,您需要
- Dify 账户(免费账户即可)。
- 一个Bright Data API 密钥。
如果您还没有这些设备,请使用上面的链接并按照说明进行设置。
先决条件
要使用 LLM 节点,您首先需要在 Dify 中设置 LLM 集成。为此,请单击您的个人资料图像并选择 “设置 “选项:
您将被重定向到允许您选择模型的页面(”模型提供程序 “选项卡)。例如,您可以安装OpenAI 提供商插件:
非常好!现在,您已经准备好开始 Dify 网络抓取工作流程了。
步骤 1:下载 Bright Data 插件并进行整合
从 Dify 官方软件仓库下载最新的Bright Data 插件包。然后按 “PLUGINS”(插件)并选择 “Install from Local Package File”(从本地软件包文件安装)选项:
选择之前下载的本地文件,然后点击 “安装 “按钮:
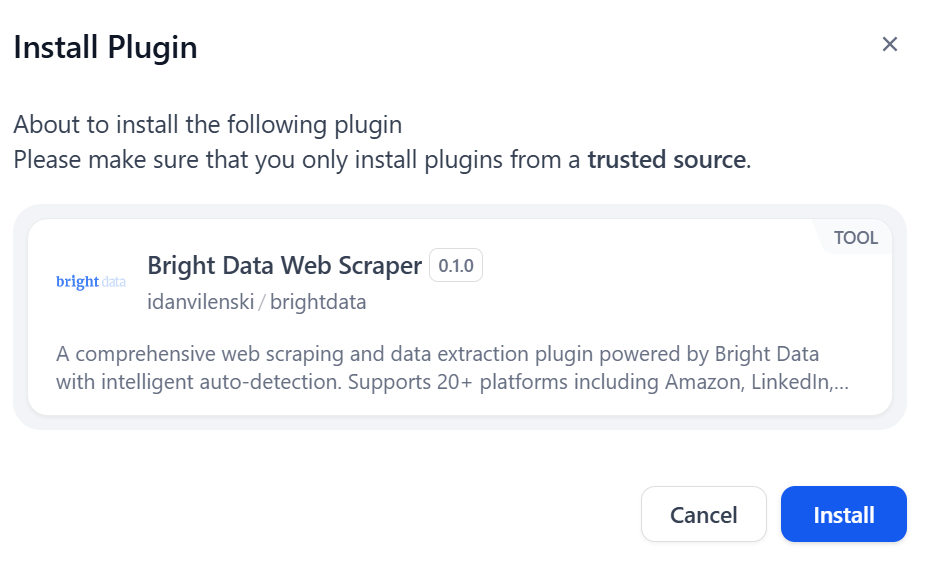
很好!Bright Data 的集成包已加载并安装到 Dify 上。
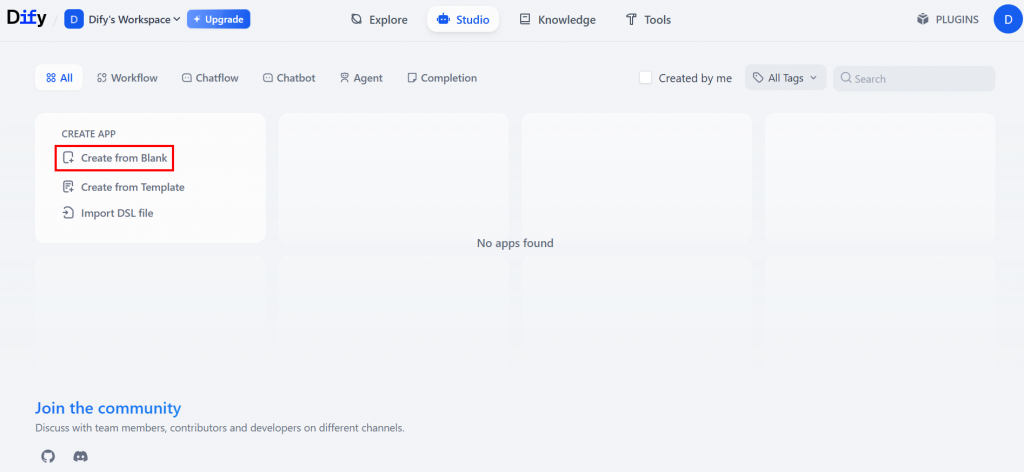
步骤 #2:创建新的 Dify 应用程序
从 Dify 工作区主页,选择 “从空白创建”,从头开始创建一个新的应用程序,如下图所示:
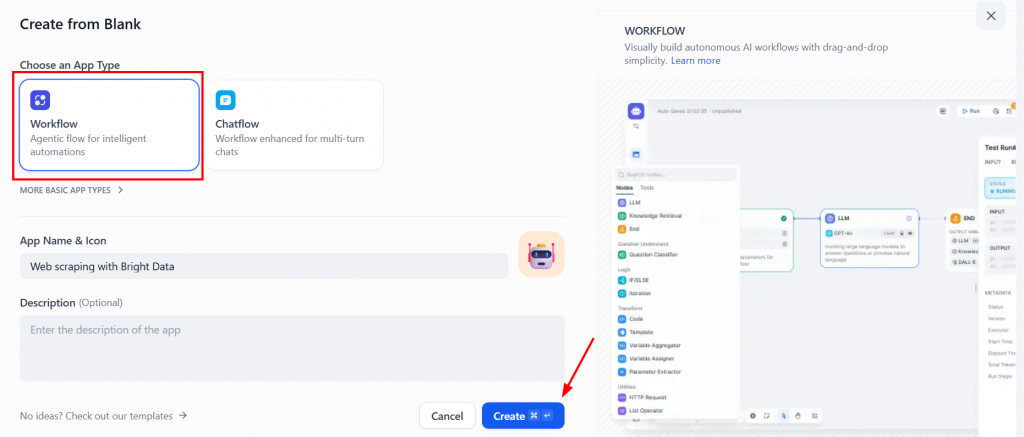
然后,选择 “工作流程 “类型,点击 “创建”:
下面是新的空白工作流程的样子:
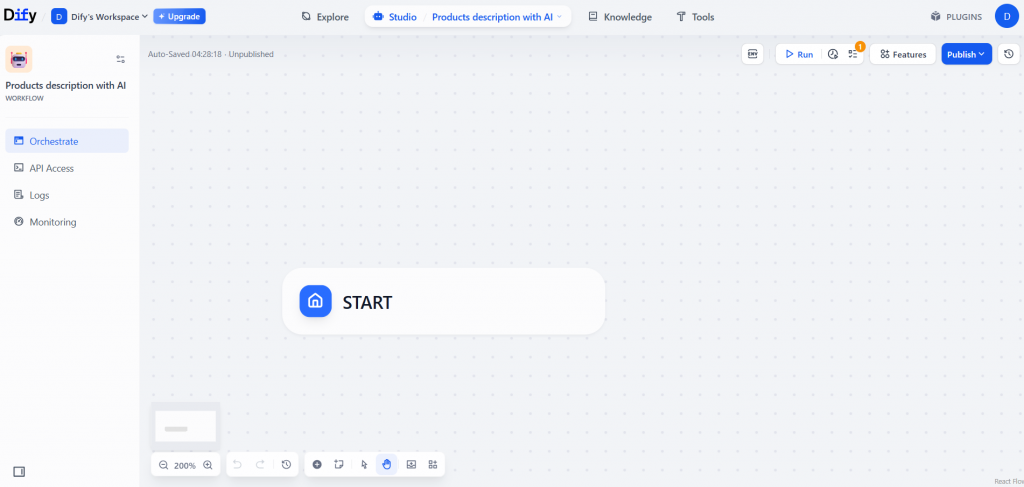
太好了!您刚刚创建了一个新的 Dify 工作流程。是时候为网络搜索添加所需的节点了。
步骤 #3:为网络抓取配置节点
现在,您可以将节点添加到工作流程中,并通过 Bright Data 为 Dify 网络抓取工作流程设置所需的参数。
首先点击 “Start(开始)”节点,然后点击 “INPUT FIELD(输入字段)”:
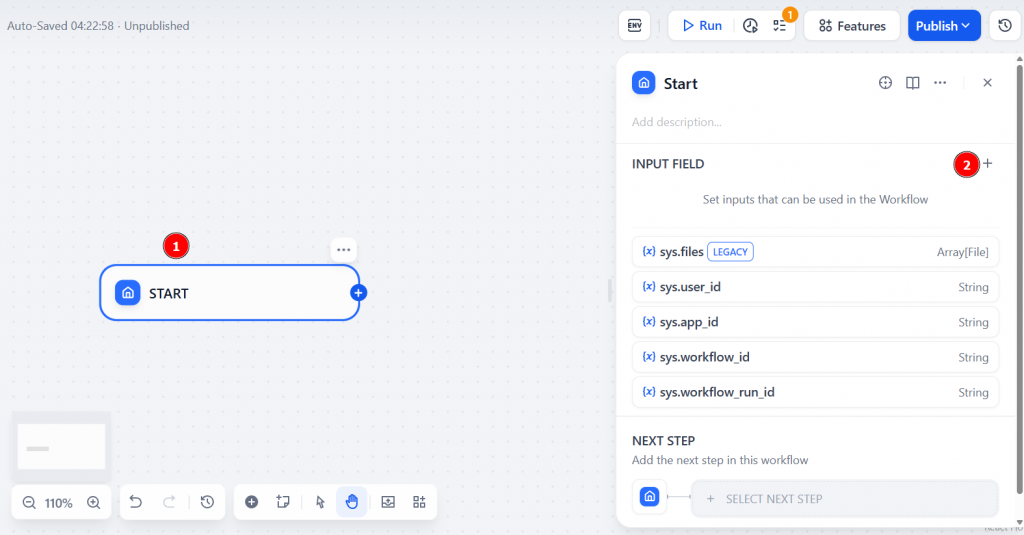
选择 “段落 “作为类型,并为 “变量名 “字段命名。例如,product_url。将 “最大长度 “值至少改为 200。这表示要抓取的目标页面的 URL。您需要通过输入来启动工作流程。
点击 “保存 “按钮确认:
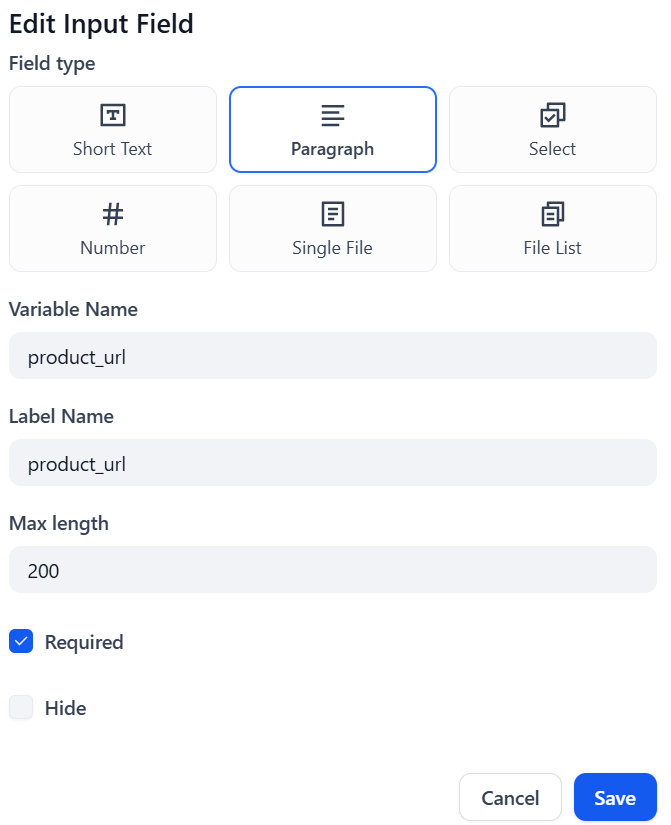
完美!启动 “节点已正确设置。
继续点击 “开始 “节点中的 “+”。选择 “工具” > “Bright Data Web Scraper” > “结构化数据源”:
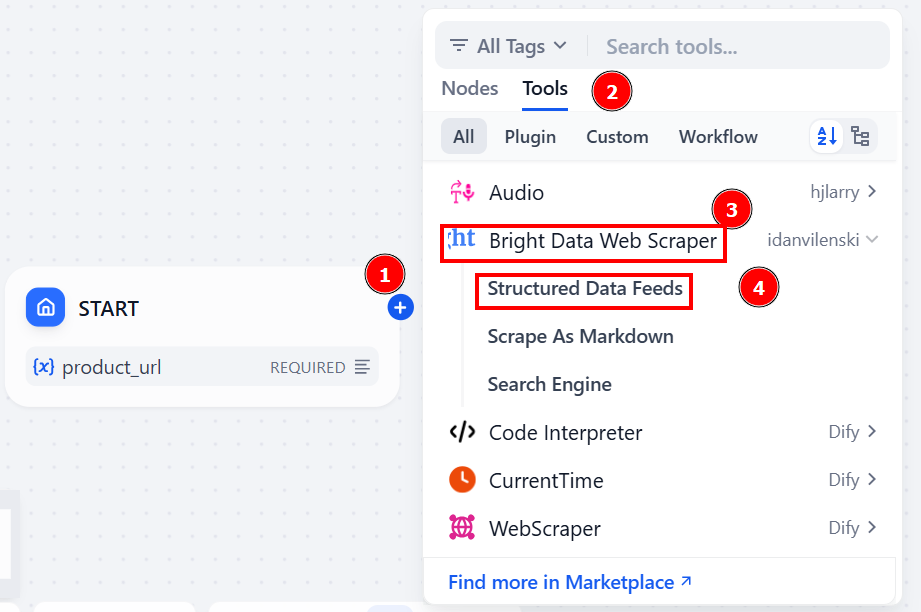
Bright Data 节点是连接 Dify 工作流程和 [Bright Data AI 基础架构](/ai)的桥梁。
/ai)的桥梁。它能让您的人工智能搜索代理从网上搜索所需的信息。
通过选择 “结构化数据源 “工具,您可以将杂乱无章的亚马逊产品页面转化为具有可预测数据字段的结构化 JSON 输出。
现在,点击 “授权”,输入您的 Bright Data API 令牌:
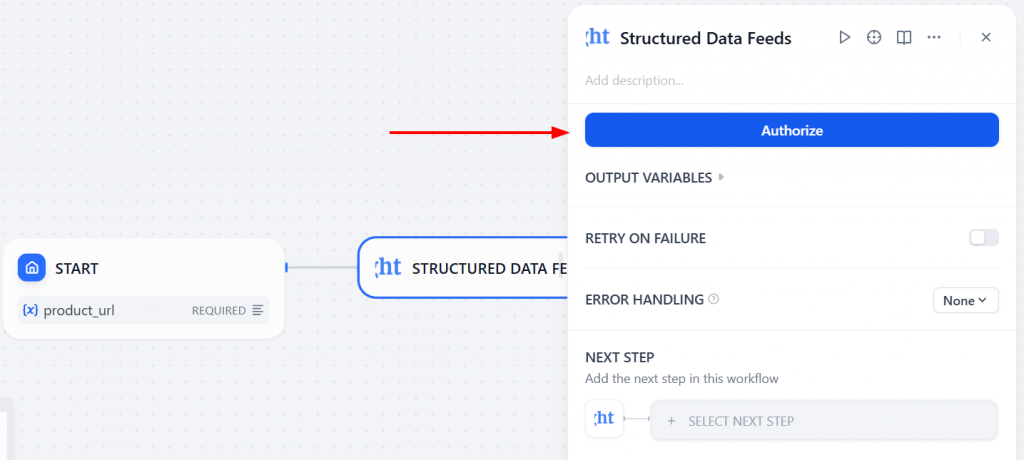
选择product_url作为输入变量。这样,”开始 “节点就会将产品 URL 的实际值作为 “亮数据 “节点的输入。
为此,请在 “目标 URL “字段中输入”/”,系统将显示可用变量列表。此外,请在 “数据请求描述 “字段中添加描述:
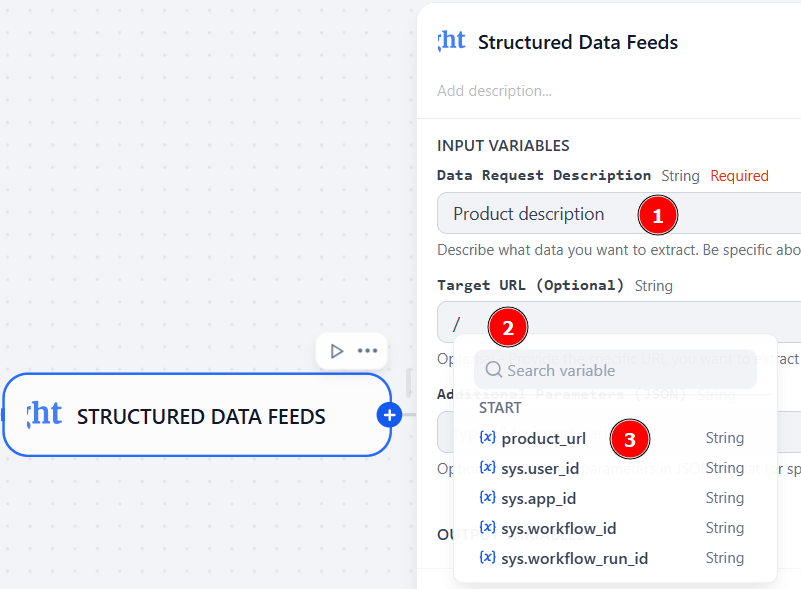
很好!Bright Data 节点已建立。您可以进入下一个节点。
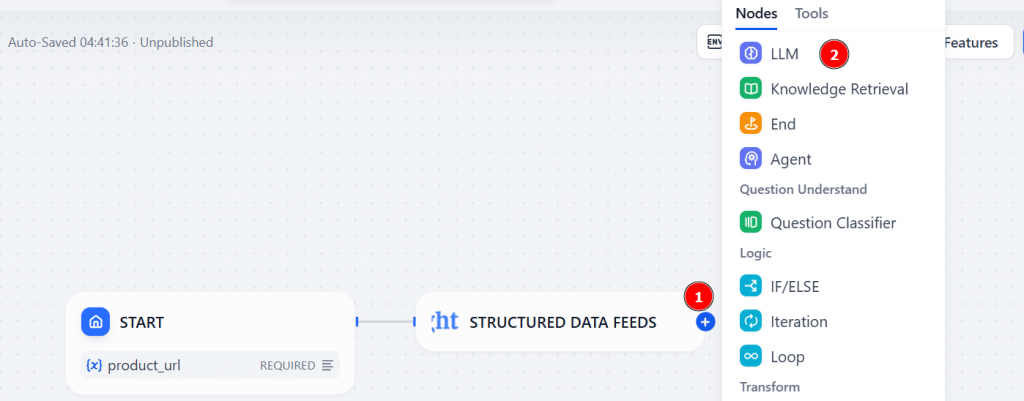
点击 “+”,添加一个 LLM 节点:
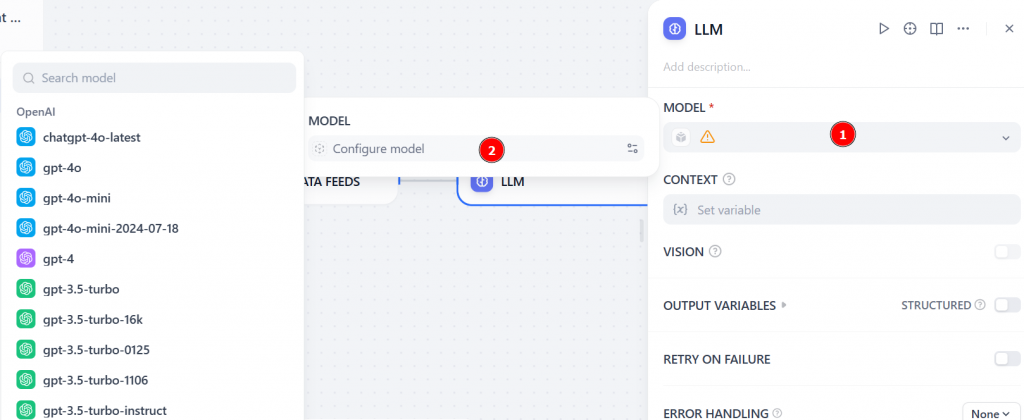
在 “MODEL(模型)”部分,选择 “Configure model(配置模型)”,然后从列表中选择一个 LLM 模型:
在 “系统 “部分,添加一个提示,例如
You are an expert e-commerce analyst. Based on the following structured data from an Amazon product page, write a concise and helpful summary for a potential buyer.
Include the following:
- Product name.
- A one-sentence summary.
- 3-5 key features in a bulleted list.
- The overall star rating and number of reviews.
- A brief concluding sentence about who this product is for.
Data:
{{Structure_Data_Feeds.text}}该提示让 LLM 扮演电子商务分析师的角色,目的是创建一份搜索到的产品摘要。它还要求提供具体细节,如产品名称和一些关键功能。请注意,它在最后包含了 Bright Data 插件节点的文本结果。
填好的部分就是这个样子:
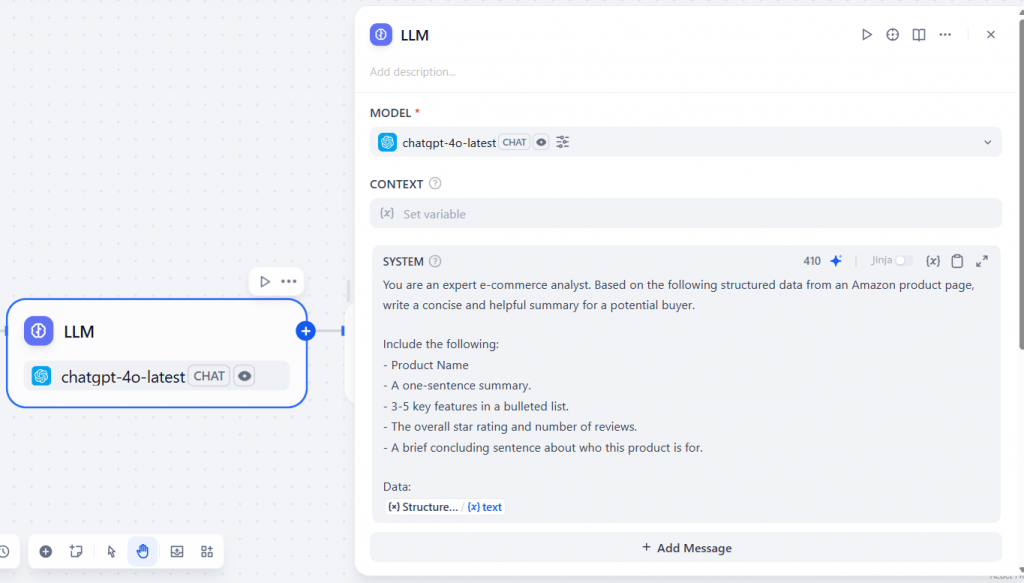
在提示的 “数据 “部分,添加文本作为输入变量。这将允许 LLM 使用 Bright Data 节点从目标 URL 获取的内容。如果点击”/”,您将获得可供选择的变量列表。
很好!现在可以将最后一个节点添加到工作流程中了。
工作流程的输出可以通过添加一个 “结束 “节点来获得:
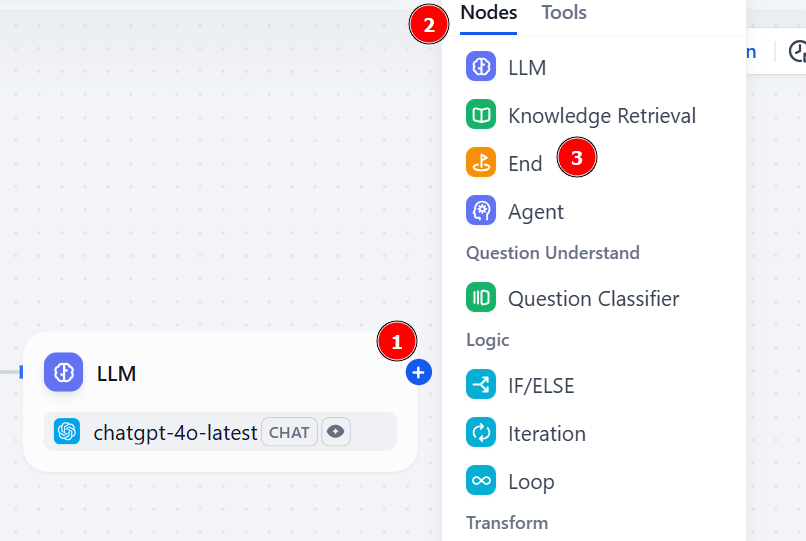
输出变量必须是来自 LLM 节点的字符串。为此,请单击 “OUTPUT VARIABLE(输出变量)”部分并选择 “LLM “下的 “text”:
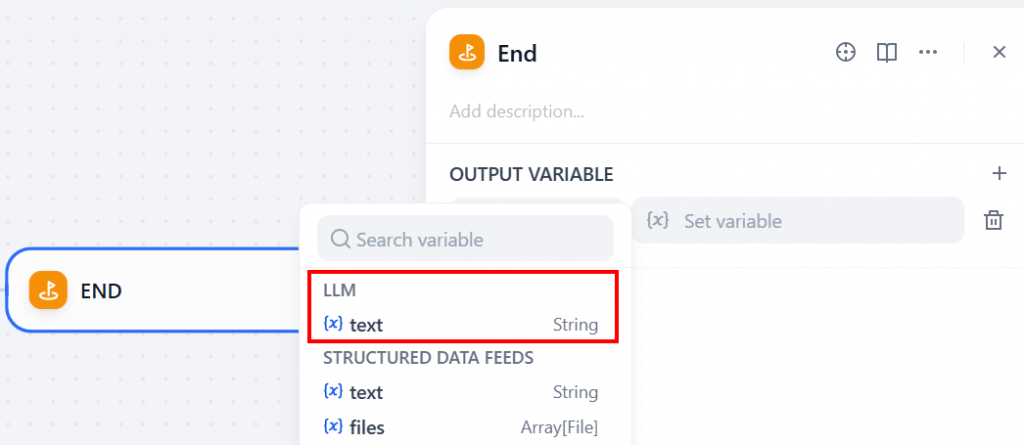
太棒了!您的工作流程已正确设置。现在就可以运行了。
步骤 #4:运行工作流程
以下是 Dify 中通过 Bright Data 插件进行网络抓取的工作流程:
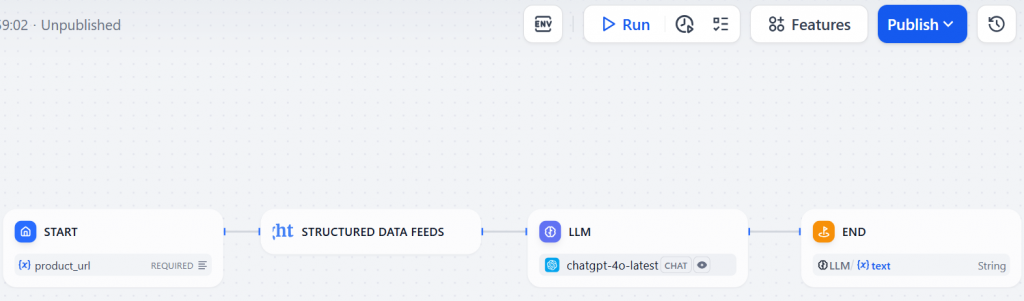
正如你所看到的,它只由四个节点组成–正如本章导言中所预期的那样。而且,你无需编写一行代码就能实现目标!
要运行工作流程,请单击 “运行”。此时,您需要在 “product_url “字段下添加亚马逊产品的 URL。然后,点击 “Start Run(开始运行)”,启动 Dify Web scraping 工作流程:
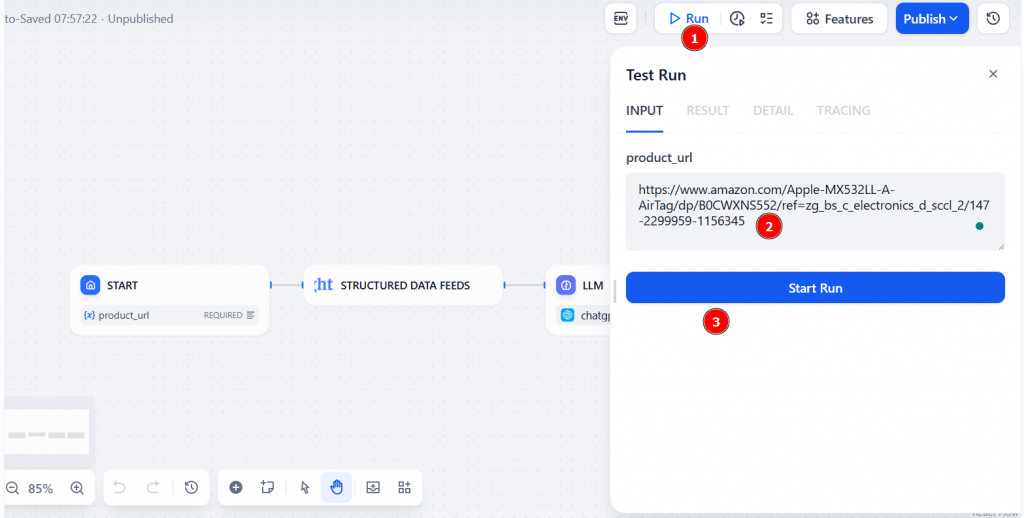
结果将在 “结果 “选项卡中显示:
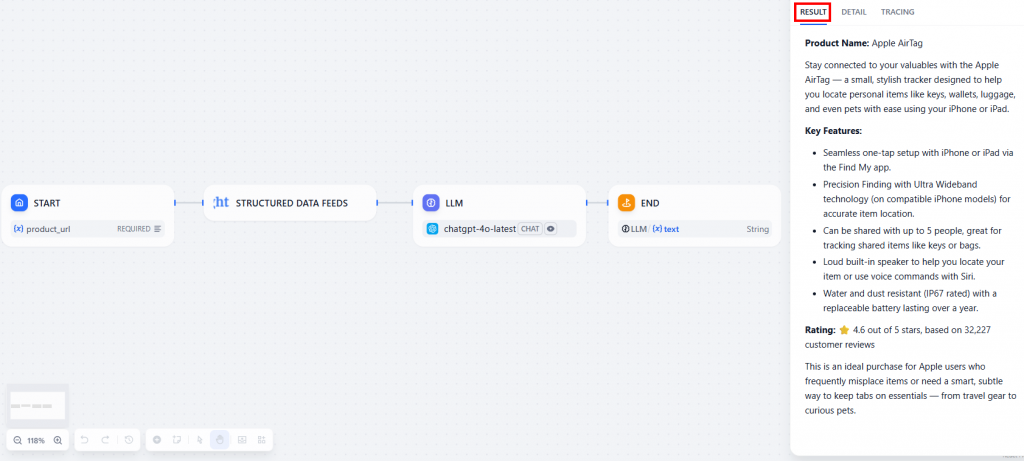
以下是文本结果:
**Product Name:** Apple AirTag
Stay connected to your valuables with the Apple AirTag — a small, stylish tracker designed to help you locate personal items like keys, wallets, luggage, and even pets with ease using your iPhone or iPad.
**Key Features:**
- Seamless one-tap setup with iPhone or iPad via the Find My app.
- Precision Finding with Ultra Wideband technology (on compatible iPhone models) for accurate item location.
- Can be shared with up to 5 people, great for tracking shared items like keys or bags.
- Loud built-in speaker to help you locate your item or use voice commands with Siri.
- Water and dust resistant (IP67 rated) with a replaceable battery lasting over a year.
**Rating:** ⭐ 4.6 out of 5 stars, based on 32,227 customer reviews
This is an ideal purchase for Apple users who frequently misplace items or need a smart, subtle way to keep tabs on essentials — from travel gear to curious pets.按照要求,法律硕士报告了您在提示中要求的内容:
- 用一句话概括产品。
- 5 项主要功能。
- 评分。
- 一个结论性的句子,说明该产品是为谁准备的。
如果你曾尝试过在亚马逊等大型电子商务网站上搜索,你就会知道这有多难:

这就是 Bright Data 集成的与众不同之处。它在幕后处理所有复杂的反抓取措施,确保数据检索过程按预期运行。
就是这样!您已成功完成将 Dify 与 Bright Data 集成的第一个项目。
结论
在本文中,您将学习如何使用 Dify 构建无代码 AI 搜索工作流程。如果没有Bright Data Dify 插件,这一切将无法实现。如图所示,该插件为人工智能工作流程中的网络抓取提供了多种高级工具。
现在,为您的人工智能代理建立可靠的抓取工作流程所面临的主要挑战之一就是如何获取高质量的网络数据。这就需要用于检索、验证和转换网络内容的工具,而这正是Bright Data 的人工智能基础架构所能提供的。
创建一个免费的 Bright Data 账户,现在就开始尝试使用我们的人工智能就绪数据工具!



技术写作者
 3 years experience
3 years experience
Federico Trotta 是一名技术写作者、编辑和数据科学家。擅长技术内容管理、数据分析、机器学习和 Python 开发。





