

Airbnb 是旅游和房地产领域最常被请求的数据源之一,也是最难收集的数据源之一:页面位于反机器人层之后并且经常变化,而在 2026 年,这些数据越来越多地为需要新鲜且结构化数据的动态定价模型和 AI 代理提供支持。本指南展示了获取它的四种方式,从普通的 Python 请求到完全托管的数据集,并为每种方式提供真实、经过测试的代码和实时输出。
本指南涵盖的内容
- 2026 年提取 Airbnb 数据的四种方式,以及何时使用每种方式
- 一个手动 Python 爬虫工具,以及它具体会在哪里失效
- 用于自定义页面的 网络解锁器,以及由你控制的解析代码
- 用于以任何规模获取干净、结构化 JSON 的 Airbnb 爬虫 API
- 用于批量和历史数据的现成 Airbnb 数据集
- 通过 Web MCP 将 Airbnb 数据提供给 AI 代理
准备跳过构建了吗? 立即使用 Airbnb 爬虫 API 提取实时房源,下载现成的 Airbnb 数据集,或免费开始,每月可获得 5,000 条记录且无需信用卡。
哪些 Airbnb 数据值得收集
单个 Airbnb 房源暴露的信息远不止每晚价格。对大多数项目而言重要的字段包括:
- 价格:每晚房价、税前总价、折扣和清洁费
- 可订状态:预订日历和最低入住晚数要求
- 评论和评分:总体评分、评论数量和类别细分
- 房东信号:超赞房东状态、回复率和历史
- 房源详情:可容纳人数、设施、坐标和图片
其中每一项都对应实时房源页面上的特定元素。下面的红框显示了结构化字段的来源:
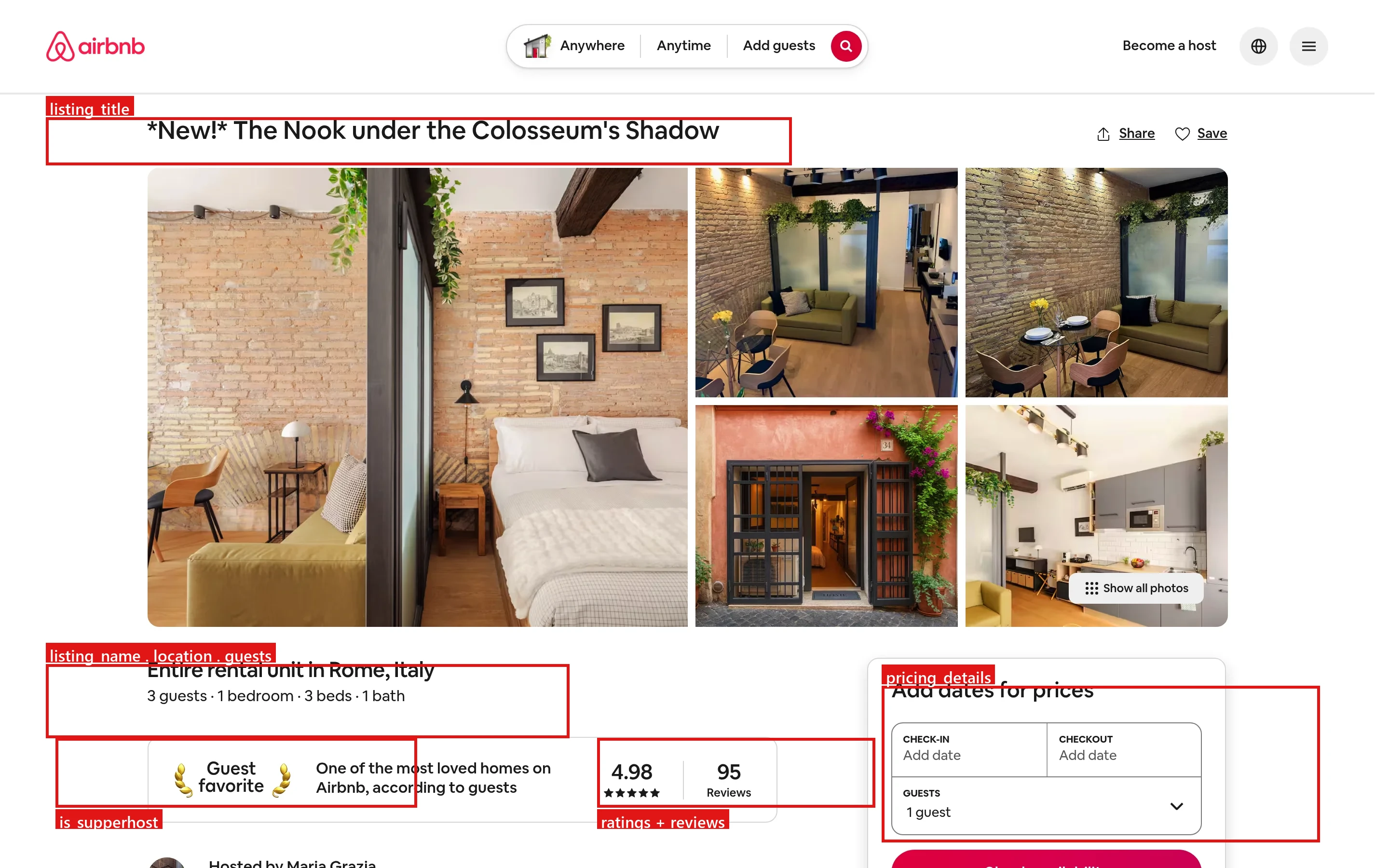
常见用例:短租投资筛选、针对本地竞争的动态定价、入住率和市场趋势分析,以及向 AI 和分析管道提供干净的位置数据。
四种方法一览
| 方法 | 工作量 | 规模 | 维护 | 最适合 |
|---|---|---|---|---|
| 手动 Python | 高 | 低 | 高 | 学习、极小的一次性提取 |
| 网络解锁器 | 中 | 中 | 中 | 自定义解析、没有预构建爬虫工具的页面 |
| Airbnb 爬虫 API | 低 | 高 | 无 | 任何规模的结构化房源数据 |
| Airbnb 数据集 | 无 | 批量 | 无 | 历史或全市场数据、无需代码 |
坦诚地总结:手动抓取是最便宜的学习方式,也是运营成本最高的方式。其他三种方式把困难部分——解锁、解析和维护——转移到托管基础设施上。
方法 1:手动抓取,以及它会在哪里失效
从显而易见的方式开始:用 requests 获取搜索页面并解析它。下面是完整尝试。
import requests
url = "https://www.airbnb.com/s/Rome, Italy/homes"
resp = requests.get(url, headers={"User-Agent": "Mozilla/5.0"}, timeout=30)
print("status:", resp.status_code)
print("DataDome anti-bot active:", "datadome" in resp.text.lower())运行后会显示你实际面对的是什么:
status: 200
DataDome anti-bot active: True请求返回 200,但每个响应都被包裹在 DataDome 的机器人检测层中。在某些尝试中,你会得到一个没有房源的挑战页面,而在另一些尝试中,单个请求会侥幸通过。这种不一致才是真正的问题:一旦你添加分页、更多城市,或任何真实的请求量,DataDome 就会标记流量,你会遇到 CAPTCHA、速率限制和 IP 封禁。要让它可靠运行,意味着需要轮换住宅代理、真实的浏览器指纹、自动化验证码破解,以及一个能承受 Airbnb 频繁标记变化的解析器。这是一个维护项目,而不是一个脚本。如果你确实想走 DIY 路线,我们的 Python 网页抓取指南涵盖了基础知识。接下来的三种方法会移除这项负担。
方法 2:用于自定义页面的 网络解锁器
当你需要原始页面时(例如,没有预构建爬虫的页面类型),网络解锁器 会处理解锁并返回完全渲染后的 HTML。你仍然自行解析数据,当你希望完全控制提取过程时,这是正确的取舍。
Airbnb 会将其房源数据作为 JSON 嵌入页面中,因此一旦你获得 HTML,就可以直接提取字段,而不需要脆弱的 CSS 选择器。
import os
import re
import requests
API = "https://api.brightdata.com/request"
payload = {
"zone": os.environ["BRIGHTDATA_UNLOCKER_ZONE"],
"url": "https://www.airbnb.com/s/Rome, Italy/homes",
"format": "raw",
"country": "us", # geo-target for consistent currency and language
}
headers = {"Authorization": f"Bearer {os.environ['BRIGHTDATA_API_KEY']}"}
html = requests.post(API, json=payload, headers=headers, timeout=120).text
names = re.findall(r'"localizedStringWithTranslationPreference":"([^"]+)"', html)
prices = re.findall(r'"accessibilityLabel":"([^"]*?\$[\d,]+[^"]*?)"', html)
print(len(set(names)), "listings parsed")
for name, price in list(zip(names[::2], prices))[:4]:
print("-", name, "|", price)这会返回真实的、已解析的房源:
30 listings parsed
- *New!* The Nook under the Colosseum's Shadow | $1,082 for 5 nights, originally $1,595
- THE BREAK - Via Frattina Maison Deluxe | $1,639 for 5 nights, originally $1,889
- The Unique Home Pantheon | $1,064 for 5 nights, originally $1,481
- 360 penthouse overlooking central Rome | $3,010 for 5 nights网络解锁器 会让你越过那堵墙,而你保留对解析的完全控制。代价是,你仍然拥有提取逻辑,并且在 Airbnb 更改页面结构时必须更新它。如果你只想要干净的房源数据,爬虫 API 会完全移除这一步。
方法 3:Airbnb 爬虫 API
Airbnb 爬虫 API 是一个预构建抓取工具。你发送房源或搜索 URL,并接收结构化 JSON。无需代理、无需解析、无需标记维护。它是 Bright Data 的 Web 爬虫工具 API 的一部分,覆盖 700+ 个网站。
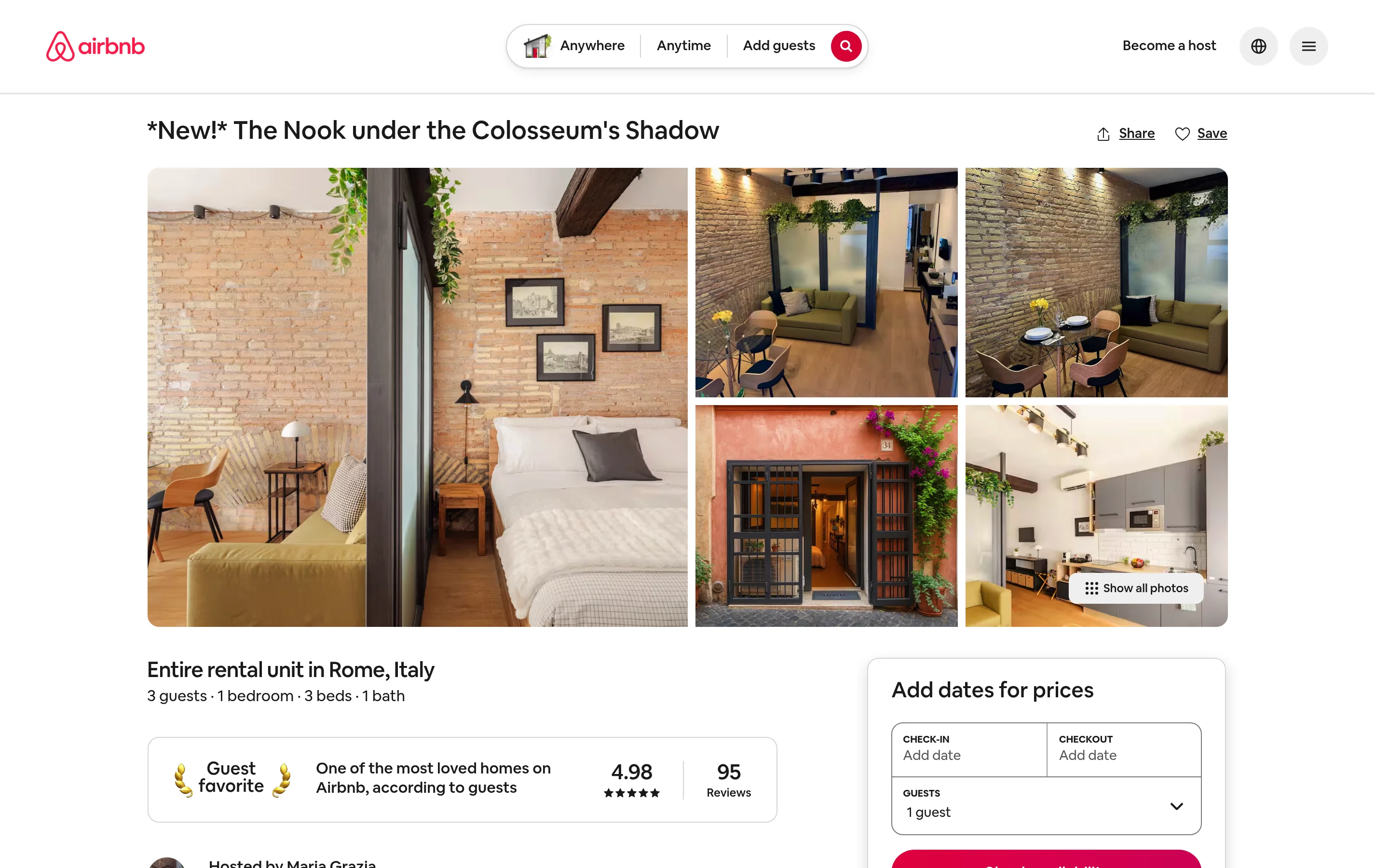
下面的示例会收集这个确切的房源,也就是你可以在 Airbnb 上实时看到的那个。
对于最多 20 个 URL,使用同步端点并在一次调用中取回结果。
import os
import requests
DATASET_ID = "gd_ld7ll037kqy322v05" # Airbnb Properties Information
TOKEN = os.environ["BRIGHTDATA_API_KEY"]
resp = requests.post(
"https://api.brightdata.com/datasets/v3/scrape",
params={"dataset_id": DATASET_ID, "format": "json"},
headers={"Authorization": f"Bearer {TOKEN}", "Content-Type": "application/json"},
json={"input": [{"url": "https://www.airbnb.com/rooms/1409274854260723534"}]},
timeout=180,
)
listing = resp.json()[0]
for field in ("listing_title", "ratings", "property_number_of_reviews",
"is_supperhost", "guests", "location", "lat", "long"):
print(f"{field}: {listing[field]}")
print("amenities:", len(listing["amenities"]), "| images:", len(listing["images"]),
"| available_dates:", len(listing["available_dates"]))响应是一个包含 51 个字段的干净记录。该房源的真实输出:
listing_title: *New!* The Nook under the Colosseum's Shadow
ratings: 4.98
property_number_of_reviews: 95
is_supperhost: True
guests: 3
location: Rome, Lazio, Italy
lat: 41.8949
long: 12.4895
amenities: 12 | images: 66 | available_dates: 185没有解析逻辑,没有代理管理,并且即使 Airbnb 更改其 HTML,模式也保持稳定。这就是抓取页面与使用维护型数据产品之间的区别。
对于更大的任务,切换到异步端点。你触发一次收集,轮询完成状态,然后下载。这可以在一个任务中扩展到数千个 URL。
import os
import time
import requests
DATASET_ID = "gd_ld7ll037kqy322v05"
TOKEN = os.environ["BRIGHTDATA_API_KEY"]
HEADERS = {"Authorization": f"Bearer {TOKEN}", "Content-Type": "application/json"}
# 1. Trigger
urls = [
"https://www.airbnb.com/rooms/1409274854260723534",
"https://www.airbnb.com/rooms/667303913003951222",
# ... hundreds more
]
trigger = requests.post(
"https://api.brightdata.com/datasets/v3/trigger",
params={"dataset_id": DATASET_ID, "format": "json"},
headers=HEADERS,
json={"input": [{"url": u} for u in urls]},
)
snapshot_id = trigger.json()["snapshot_id"]
# 2. Poll until ready
while True:
status = requests.get(
f"https://api.brightdata.com/datasets/v3/progress/{snapshot_id}",
headers=HEADERS,
).json()["status"]
if status == "ready":
break
if status == "failed":
raise RuntimeError("collection failed")
time.sleep(10)
# 3. Download
data = requests.get(
f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}",
params={"format": "json"},
headers=HEADERS,
).json()
print(len(data), "listings collected")你只为交付的记录付费,Web 爬虫工具 API 起价为每 1,000 条记录 0.70 美元,并且每个新账户每月都会获得 5,000 条免费记录用于测试,无需信用卡。如果你不想编写这些内容,控制面板中也有无代码版本。
方法 4:现成的 Airbnb 数据集
如果你需要历史或全市场覆盖,而不是特定 URL 列表,请完全跳过收集并购买 Airbnb 数据集。它是相同的结构化模式,已预先收集并刷新。
市场数据集包含 650 万+ 条记录,覆盖 51 个字段,价格从每条记录 0.0025 美元起,最低订单 250 美元,可作为一次性下载或刷新订阅。你可以按位置、日期或其他属性筛选,并以 JSON、CSV 或 Parquet 下载。这是购买与构建的选项:零工程投入、即时访问,并且非常适合回测定价模型或一次性分析整个城市。Bright Data 也为其他市场发布相同的即用型数据,包括最佳 Amazon 数据提供商和最佳电商数据提供商。
奖励:将 Airbnb 数据直接提供给 AI 代理(MCP)
2026 年最大的转变是,这些数据的消费者通常是 AI 代理,而不是控制面板。代理需要按需获取实时网页数据,而模型上下文协议(MCP)就是它们调用外部工具的方式。Bright Data 的 Web MCP 服务器为任何 LLM(无论是 Claude、GPT 还是 Gemini)提供实时搜索(搜索引擎 API)和通过相同解锁基础设施进行的抓取,因此代理永远不会遇到方法 1 中的 DataDome 墙。
用一行代码将你的 MCP 客户端指向托管服务器,无需安装:
https://mcp.brightdata.com/mcp?token=YOUR_API_TOKEN或者使用 npx 在本地运行:
{
"mcpServers": {
"Bright Data": {
"command": "npx",
"args": ["@brightdata/mcp"],
"env": { "API_TOKEN": "your-token-here" }
}
}
}更快的是,Bright Data CLI 用一条命令将 MCP 接入你的代理:
brightdata add mcp, agent claude-code,cursor,codex免费的 Rapid 模式以每次请求一个积分暴露 search_engine、scrape_as_markdown 和 discover,并从同样的每月 5,000 个免费积分中扣除。然后,代理可以通过实时搜索和爬虫来回答类似“查找罗马每晚低于 200 美元的可订 Airbnb 房源,并总结最便宜的五个”这样的提示,而你的应用中无需任何抓取代码。Pro 模式增加了 60+ 个结构化工具,包括预构建的网页数据提取器和抓取浏览器自动化,适用于生产代理。完整演练请参阅 Web MCP 抓取教程。
在将其接入代理之前,你可以先用 Bright Data CLI 从终端尝试完全相同的工具,它会从同样的免费积分中扣除。针对 Airbnb 的快速 search 和 scrape:
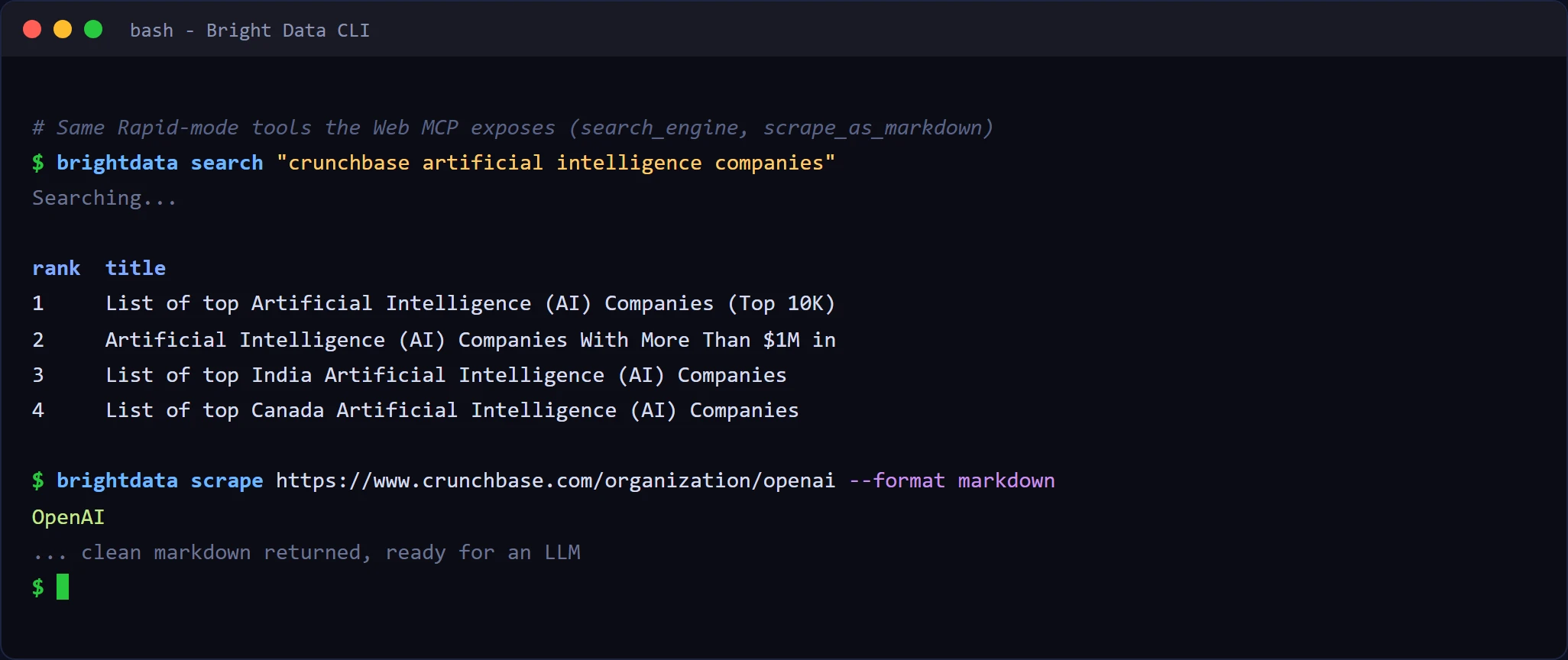
CLI 的 search 和 scrape 与 MCP 的 search_engine 和 scrape_as_markdown 工具一一对应,因此你终端中返回的内容,正是代理连接后会接收的内容。
查看它在代理内部如何工作
连接后,你用自然语言提问,代理会决定调用哪些 MCP 工具。开箱即用的提示:
- “在罗马的 Airbnb 上查找出租公寓,并推荐几个带评分的。”
- “提取 airbnb.com/rooms/ID 的关键详情:评分、超赞房东状态、可容纳人数。”
- “比较罗马和佛罗伦萨两居室 Airbnb 的每晚价格。”
- “用三个要点总结这个房源的评论情绪。”
下面是第一个提示在 Claude Code 中运行。代理自行调用 search_engine 和 scrape_as_markdown,然后用实时数据回答,项目中没有抓取代码。
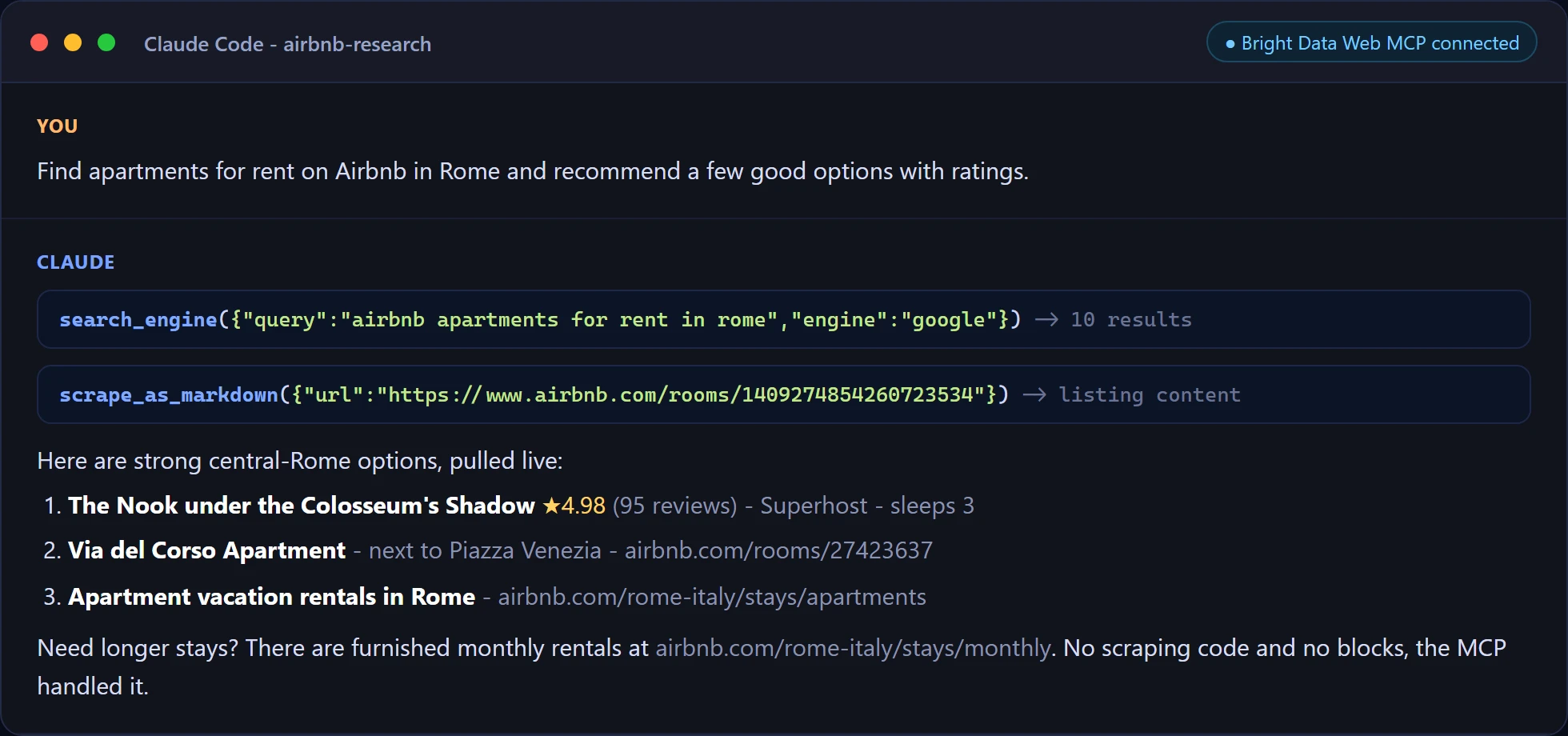
以及在 Cursor 中的定向提取,直接从实时页面提取一个房源的字段。
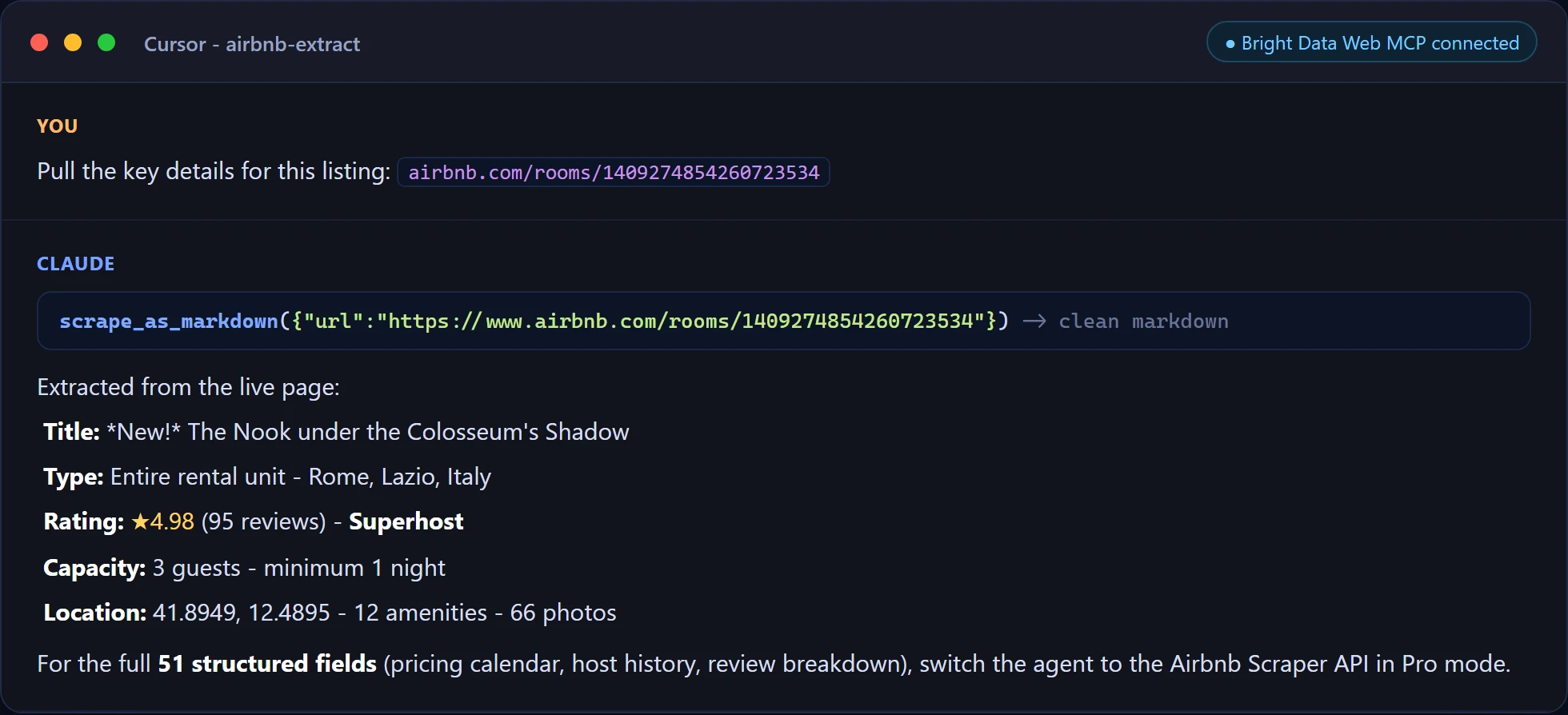
对于需要每个字段的生产代理,启用 Pro 模式,代理就会获得 60+ 个结构化网页数据工具,可与方法 3 中的 Airbnb 爬虫 API 一起调用。
将数据转化为洞察
获得房源后,分析会很快。使用方法 2 中解析的价格,一个短代码片段即可总结本地市场。
import statistics
prices = [1082, 1639, 1064, 3010, 904, 1115, 2008, 1398] # USD, 5-night totals
print("listings:", len(prices))
print("median:", statistics.median(prices))
print("range:", min(prices), "to", max(prices))绘制完整样本,可以一眼看到罗马市中心的价格分布。
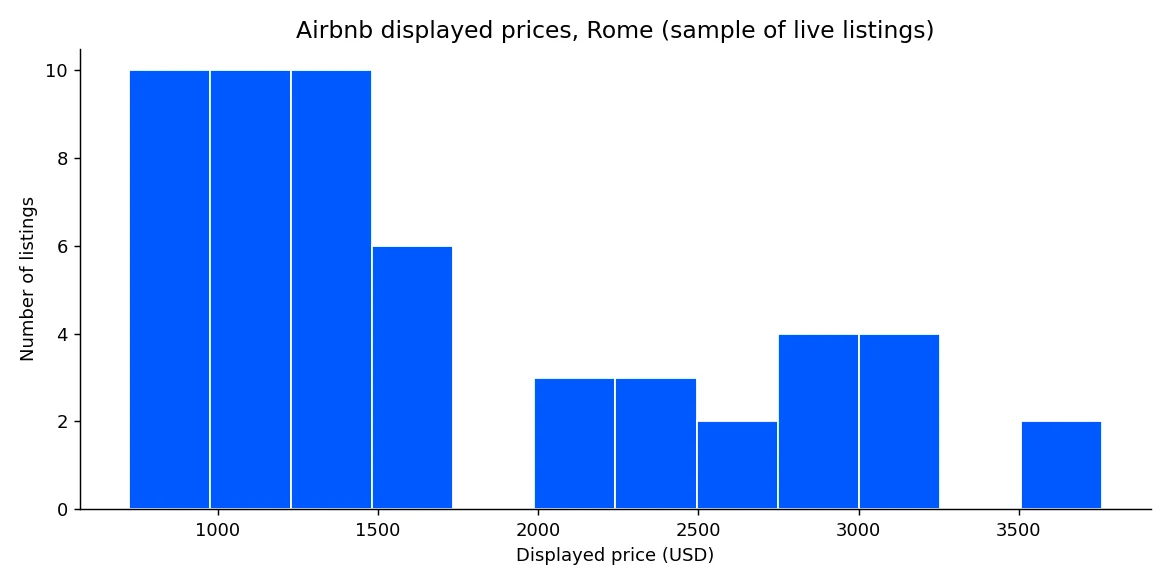
该分布是竞争性定价、异常值检测和入住率建模的基础。
如何选择
- 只是探索或学习? 手动抓取会教你页面是如何构建的。不要在生产中运行它。
- 需要一个没有预构建爬虫工具的页面,并且想自行负责解析? 使用 网络解锁器。
- 需要任何规模的干净、结构化房源数据? 使用 Airbnb 爬虫 API。这是大多数项目的默认选择。
- 需要无需代码的历史或全市场数据? 使用 Airbnb 数据集。
对于专用工具的正面对比,请参阅我们的最佳 Airbnb 爬虫工具和最佳 Airbnb 数据提供商汇总。
贯穿所有这些方法的模式是:让托管基础设施处理解锁和结构化,这样你的团队就能把时间花在分析上,而不是看管抓取工具。Bright Data 的网络正是为此而构建的,每次请求背后都有符合 GDPR 和 CCPA、通过 ISO 27001 认证、以道德方式获取的基础设施。
结论
在 2026 年抓取 Airbnb,重点不再是聪明的解析,而是选择正确的抽象层级。手动代码适合学习,但会在 Airbnb 的反机器人层下失效。网络解锁器 在你需要自定义控制时为你提供页面。Airbnb 爬虫 API 以零维护提供结构化记录。数据集以零代码提供整个市场。先使用爬虫 API 上的 5k 请求,将其指向你关心的房源,然后在此基础上构建。
常见问题
我可以用普通的 Python requests 爬虫 Airbnb 吗?
不能可靠地做到。Airbnb 使用 DataDome 机器人检测保护其页面。默认请求通常会返回挑战页面,即使某个请求侥幸通过,在规模化时也会因 CAPTCHA、速率限制和 IP 封禁而失效。你需要托管解锁、真实浏览器指纹和代理,这也是为什么大多数团队使用 网络解锁器 或 Airbnb 爬虫 API。
Airbnb 爬虫 API 可以返回哪些数据?
单条记录包括 51 个字段:房源标题和类型、每晚和总价、可订日历、评分和评论数量、房东和超赞房东信号、设施、坐标、图片等。你会以干净 JSON 的形式接收它,无需解析。
我应该使用爬虫 API 还是现成数据集?
当你有特定房源或搜索 URL,并希望按需获取新鲜数据时,使用爬虫 API。当你需要历史或全市场覆盖且无需提供 URL 时,使用数据集。该数据集包含 650 万+ 条记录,起价为每条记录 0.0025 美元。
开始需要多少费用?
每个新的 Bright Data 账户每月在 Web 爬虫工具 API、网络解锁器 和 搜索引擎 API 中包含 5,000 条免费记录,无需信用卡。除此之外,Web 爬虫工具 API 起价为每 1,000 条记录 0.70 美元,并且你只为交付的数据付费。
AI 代理可以通过 MCP 收集 Airbnb 数据吗?
可以。Bright Data 的 Web MCP 服务器将任何兼容 MCP 的 LLM(Claude、GPT、Gemini)连接到实时网页数据。在免费的 Rapid 模式中,代理以每次请求一个积分获得 search_engine 和 scrape_as_markdown,因此它可以按需提取当前 Airbnb 房源,而你的应用中无需任何爬虫代码。Pro 模式为生产代理增加了 60+ 个结构化数据工具。
如何处理大型 Airbnb 爬虫任务?
使用异步端点:用你的 URL 列表触发一次收集,轮询进度端点直到快照就绪,然后以 JSON、CSV 或 NDJSON 下载。单个任务可处理数千个 URL,并且快照可用 30 天。



高级 SEO 专家
 6 years experience
6 years experience
Daniel Shashko 是 Bright Data 的高级 SEO/GEO 专家,专注于 B2B 营销、国际 SEO,以及开发 AI 驱动的代理、应用与网页工具。




