

在本文中,你将学到:
- 什么是多模态 AI,以及它为何对现代应用至关重要。
- Bright Data 如何通过网页数据采集,助力多模态 AI 的落地实施。
- 如何利用 Bright Data 的工具,按步骤搭建一个可运行的多模态 AI 应用。
让我们开始吧!
什么是多模态 AI?
多模态 AI 指的是能够同时处理、理解并从多种类型(或“模态”)数据中生成洞察的人工智能系统。这些数据类型包括文本、图像、视频、音频以及结构化数据。
例如,它可以接收一张饼干的照片,并生成一份文字版食谱作为回应,反之亦然。

这种融合使得更多强大而细腻的应用成为可能,例如:
- 高级内容分析:通过同时分析图片和文字说明,理解一个表情包的真实语境。
- 智能电商:结合商品图片中的视觉风格和评论中的文字偏好,推荐更合适的商品。
- 强化科研能力:从包含图表、示意图和正文内容的科研论文中提取结构化数据。
你可以把多模态 AI 理解为让电脑同时拥有“眼睛”和“耳朵”,既能读文字,又能看图片。
为什么 Bright Data 是构建多模态 AI 应用的关键
构建一个多模态 AI 应用,首先需要一个关键基础:多样化、高质量且可扩展的数据。这正是 Bright Data 作为合作伙伴不可或缺的原因。
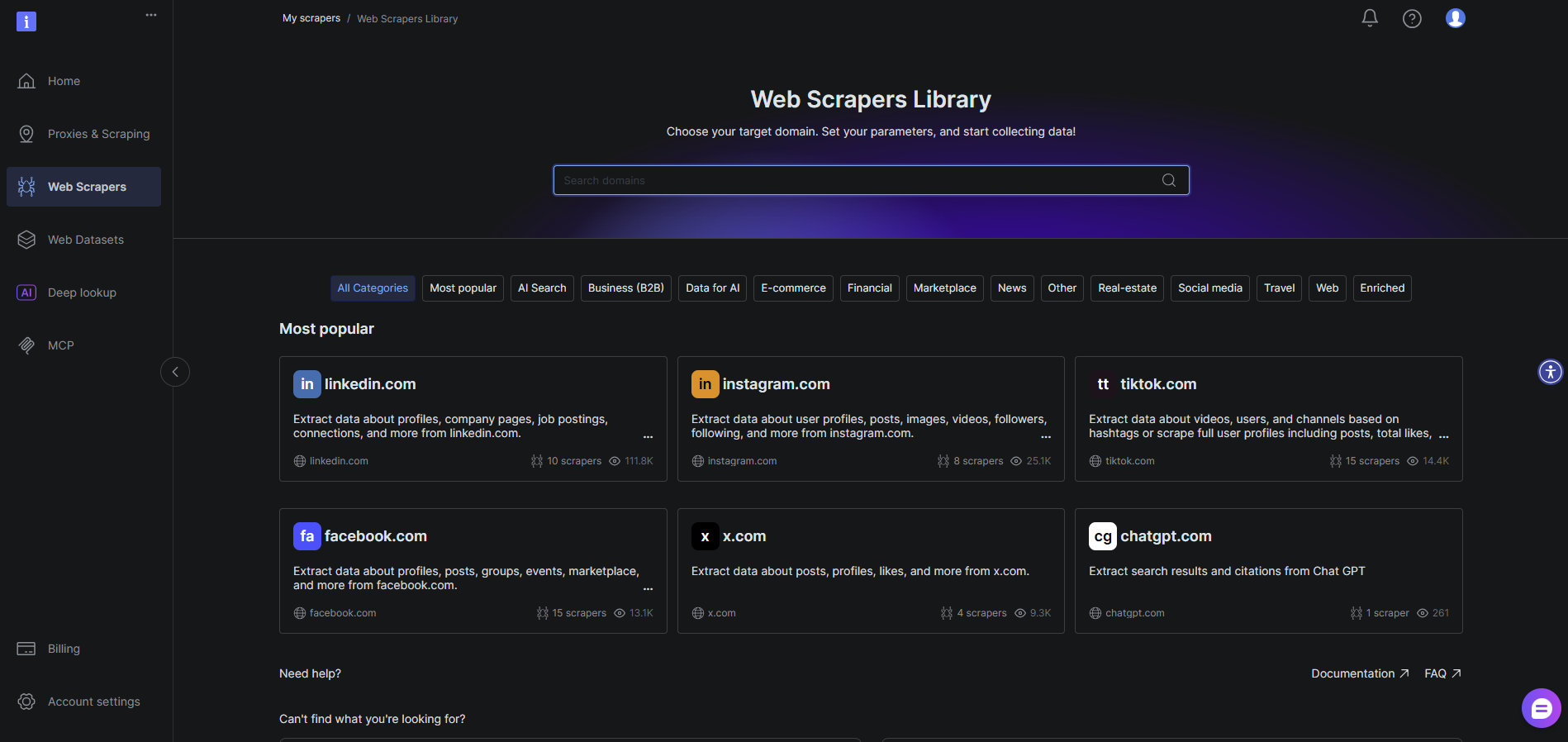
获取多元数据源
多模态 AI 需要摄取丰富多样的数据类型。Bright Data 能够无缝获取来自整个公开网络的文本、图片、视频以及结构化数据。无论是抓取电商网站的商品图片与描述、分析带有配图的社交媒体帖子,还是收集嵌入多媒体内容的新闻文章,Bright Data 的基础设施与工具(如 Web Scraper API 和 Datasets)都可以帮助你在同一套工作流中获取所有这些模态的数据。
企业级数据质量保障
AI 模型的效果取决于训练或输入的数据质量。Bright Data 确保你采集的数据干净、可靠且准确。借助 自动 IP 轮换、CAPTCHA 处理 以及 JavaScript 渲染等能力,Bright Data 能像真实用户浏览一样,获取完整且未被屏蔽的数据。这种质量保障对于构建可投入生产环境、结果稳定可信的 AI 应用来说是不可妥协的。
面向生产场景的可扩展性
做出一个 PoC 和运行一个真正的线上应用,是两件完全不同的事。Bright Data 的全球代理网络与稳健基础设施天生面向规模化场景。你可以同时从成千上万个来源采集多模态数据,而无需担心封锁、封禁或访问速率限制,确保你的 AI 应用能够随着用户需求不断扩展。
如何使用 Bright Data 构建多模态 AI 应用
下面我们将一起搭建一个实用的应用。这个工具会使用 Bright Data 抓取某个商品页面,收集图像与文本数据,然后将其发送给多模态 AI 模型(如 GPT-4 Vision),生成结构化分析结果。
前置条件
- 一个 Bright Data 账号。
- 一枚具有 gpt-4-vision-preview 访问权限的 OpenAI API 密钥,或一枚 Anthropic API 密钥。
- 已安装的 Node.js(v18+)或 Python 运行环境。
- 具备基础的 API 集成知识。
步骤 1:为多模态数据采集配置 Bright Data
我们将使用 Bright Data 的 Web Scraper API,它易于使用并支持 JavaScript 渲染——这对抓取现代、动态的商品页面至关重要。
- 登录 Bright Data Web Scraper。
- 创建一个新的 scraper。本示例中,我们以某个示例商品页面为目标。
- 输入你的目标 URL。
- 在“Parsing Instructions”中复制并粘贴以下 JSON。
Scraper 配置示例(Bright Data 界面中):
{
"title": ".product-title",
"image_url": ".main-product-image img | attr:src",
"description": ".product-description",
"price": ".price",
"specs": ".specifications-table"
}步骤 2:配置多模态 AI 模型
现在你的数据采集链路已经准备就绪,接下来我们要接入本项目的AI 大脑——OpenAI 的 gpt-4-vision 模型。
该模型能够理解文本和图像,非常适合我们的多模态场景。
1. 获取 API Key
打开你的 OpenAI 控制台,创建一枚新的 API 密钥。
请妥善保管这枚密钥,稍后你将在代码中用到它。
2. 配置开发环境
我们会使用 Node.js 或 Python 来运行本项目,你可以根据个人偏好选择。
在项目目录中打开终端,然后安装官方 OpenAI SDK:
Node.js:
npm init
npm install openaiPython:
pip install openai安装完成后,你就可以在下一步向模型发送第一条请求。
步骤 3:使用 Bright Data 采集网页数据
模型准备就绪后,我们来通过 Bright Data 采集真实世界的数据。
这是项目“活起来”的关键步骤:我们将从实际商品页面中获取文本和图片数据。
1. 连接 Bright Data API
打开项目的主脚本文件(如 index.js 或 main.py),添加以下代码以连接 Bright Data 的 Web Scraper API。
Node.js 示例:
import fetch from "node-fetch";
const BRIGHTDATA_API_KEY = "YOUR_BRIGHTDATA_API_KEY";
const SCRAPER_ID = "YOUR_SCRAPER_ID";
const response = await fetch(
`https://api.brightdata.com/datasets/v3/run?dataset_id=${SCRAPER_ID}`,
{
method: "POST",
headers: {
Authorization: `Bearer ${BRIGHTDATA_API_KEY}`,
"Content-Type": "application/json",
},
body: JSON.stringify({
url: "https://example.com/product-page", // Replace with an actual product URL
}),
}
);
const scrapedData = await response.json();
console.log("Collected Multimodal Data:", scrapedData);
const scrapedData = await response.json();
console.log("Collected Multimodal Data:", scrapedData);2. 校验采集结果
运行该脚本后,你应该能在控制台看到结构化的商品数据输出。
结果大致如下(具体值会随目标 URL 变化):
{
"title": "Wireless Noise-Cancelling Headphones",
"image_url": "https://examplecdn.com/headphones.jpg",
"description": "Premium over-ear headphones with active noise cancellation and 30-hour battery life.",
"price": "$199.99",
"specs": {
"battery_life": "30 hours",
"connectivity": "Bluetooth 5.2",
"color": "Black"
}
}这个输出说明你的 Bright Data 配置已经正确运行,并返回了文本和图片两种输入,是进行多模态 AI 分析的理想基础。
步骤 4:处理并结构化数据
现在我们已经通过 Bright Data 抓取到原始商品数据,接下来要为多模态 AI 模型进行整理和准备。
目标是给模型提供一切所需:干净的文本、清晰的图片引用,以及一个结构化的提示,让它明确该如何处理。
1. 格式化商品数据
我们将抓取到的数据整理成一段结构良好的模型输入信息。
Node.js 示例:
// Assume scrapedData contains the product info returned from Bright Data
const productAnalysisPrompt = `
Analyze this product and provide a structured summary. Use both the product image and text data.
Product Details:
- Title: ${scrapedData.title}
- Description: ${scrapedData.description}
- Price: ${scrapedData.price}
- Specifications: ${JSON.stringify(scrapedData.specs)}
Based on the image and text, please answer:
1. What is the primary use case for this product?
2. List 3 key features visible or described.
3. Evaluate the product’s perceived quality and value.
`;
const imageUrl = scrapedData.image_url;这里我们做了:
- 将所有文本数据整合到一条详细的 Prompt 中。
- 单独保存图片 URL,便于模型进行视觉分析。
2. 测试数据结构
在调用模型前,先打印变量,确认内容干净可读。
console.log("Prompt Preview:", productAnalysisPrompt);
console.log("Image URL:", imageUrl);如果文本可读、且图片 URL 以 https:// 开头,就可以进入下一步,将其送入多模态 AI 模型。
步骤 5:向多模态 AI 模型发送数据
接下来是最精彩的部分:将文本 + 图片组合数据发送给多模态 AI 模型,获取智能分析结果。
我们将使用 OpenAI 的 gpt-4-vision 模型,它可以在一次请求中同时“看图”和“读文”,生成详细分析。
1. 初始化 OpenAI 客户端
我们通过官方 OpenAI SDK 连接 API。
Node.js 示例:
import OpenAI from "openai";
const openai = new OpenAI({ apiKey: "YOUR_OPENAI_API_KEY" });2. 创建多模态请求
下面我们将格式化后的商品文本和图片 URL 一并发送到模型。
const completion = await openai.chat.completions.create({
model: "gpt-4-vision-preview",
messages: [
{
role: "user",
content: [
{ type: "text", text: productAnalysisPrompt },
{ type: "image_url", image_url: { url: imageUrl } },
],
},
],
max_tokens: 1000,
});
const aiResponse = completion.choices[0].message.content;
console.log("AI Analysis Result:", aiResponse);
const aiResponse = completion.choices[0].message.content;
console.log("AI Analysis Result:", aiResponse);3. 解读模型返回结果
运行后,你会获得类似如下的结构化分析:
The product appears to be premium wireless over-ear headphones designed primarily for travelers and professionals who need noise isolation in noisy environments.
Key features include:
1. Active noise cancellation technology visible from the ear cup design
2. 30-hour battery life mentioned in specifications
3. Premium matte black finish visible in the image
The headphones present as high-quality based on the visible materials and the detailed technical specifications provided. The price point suggests a premium market positioning.步骤 6:处理并展示结果
现在模型已经给出了分析结果,我们来对输出进行整理,从而更清晰地呈现。
你可以先在控制台中简单输出,也可以之后在 Web 控制台中以更精美的方式展示。
1. 格式化 AI 输出
下面我们将模型返回的纯文本结果进行整齐输出。
Node.js 示例:
console.log("=== PRODUCT INTELLIGENCE ANALYSIS ===");
console.log(aiResponse);
// (Optional) Save the output to a file
import fs from "fs";
fs.writeFileSync("analysis_output.txt", aiResponse);
console.log("Analysis saved to analysis_output.txt");如果你希望集中存储结果以便后续使用,也可以将其保存到数据库,或在一个简单的 React 前端中展示。
2.(可选)创建一个基础 Web 预览页面
如果你想要更直观的体验,可以通过本地 Web 页面提供可视化展示。
简易 Node.js 服务示例:
import express from "express";
import fs from "fs";
const app = express();
app.get("/", (req, res) => {
const result = fs.readFileSync("analysis_output.txt", "utf8");
res.send(`
<h2>Product Intelligence Analysis</h2>
<pre>${result}</pre>
`);
});
app.listen(3000, () =>
console.log("Server running at http://localhost")
);打开浏览器访问 http://localhost,你就能看到模型生成的分析结果以纯文本方式整齐呈现。
总结
多模态 AI 是一次重要的技术飞跃,让应用能够以更接近人类的方式理解这个世界。正如我们在本文示例中展示的那样,要真正释放多模态 AI 的潜力,高质量、多样化且可扩展的真实世界数据是关键。
扩展与实验
你可以在这个项目基础上继续拓展:
- 增加更多数据源:从电商网站抓取商品评论或相关视频,进行更深度的分析。
- 接入前端:使用 React 或 Next.js 将 AI 输出展示在一个干净的可视化仪表盘中。
- 自动化报告:定时执行每日抓取和分析,用于竞品商品的持续监控。
每向前迈出一步,都能让你的项目更接近生产级的 AI 数据智能解决方案。
准备好用全球领先的网络数据来驱动你的 AI 项目了吗?
- 立即注册 Bright Data,获取免费额度并开始实践。
- 尝试本文的代码示例,将其应用到不同网站,并探索 Bright Data 生态中的其他工具,例如 Data Collector 或现成的 Datasets。
从现在开始,构建下一代智能应用。



技术写作者
Amitesh Anand 是一位开发者倡导者和技术写作者,分享有关 AI、软件和开发工具的内容,拥有 1 万粉丝和超过 40 万次观看。





